|
|
词元之后:AI时代真正稀缺的是什么?
【前置声明】
本文是基于我个人三十余年跨领域实践(从1989年赴澳留学至今,涉及远程工作、物流管理、自动化处理、网站建设、文化传播、多语言出版以及跨领域研究)所形成的个人观点。词元是正在快速演变的新事物,本文仅代表
截至成文时(2026年6月)的个人阶段性观察与判断,不构成任何形式的投资建议、商业预测或行业标准。
本文不追求普遍适用性,也不声称代表任何行业共识。随着词元市场、AI技术和全球政策环境的持续变化,本文中的部分判断可能在未来需要修正或更新。读者应结合最新信息独立判断。
我所论述的“五种稀缺能力”及“五项个人资产”,均来自我个人的系统构建实践(公开实证见 https://times.net.au 及该网站列出的全部40+部独立创作作品、ISSN
3083-5178、超60个DOI、以及被WorldCat、澳大利亚国家图书馆、CERN
Zenodo等国际基础设施永久存档的记录)。
为了避免断章取义,任何针对本文的有效反驳或质疑,其前提条件是:完整浏览本文所有链接文章及其中的嵌套链
接,并完整阅读我在 https://times.net.au 列出的全部作品。脱离这一整体语境的局部引用或简化概括,均无法构成对本文的公正评价。
关于有效反驳的补充说明:
本文为个人观点,不追求普遍适用性,亦不以引用他人文献为前提。任何有效质疑应采用对等比较(APPLE
TO APPLE):以当前事实对当前事实,以个人实践对个人实践,以已完成系统对已完成系统。用“未来AI可能做到”否定“当前已完成的实践”,或以团队/机构能力对标个人实践,均不构成对等比较。
本文所述五项资产组合为个人实践记录,未声称“不存在任何对标案例”。若认为存在完全对标的案例,请举出具体公开案
例,并说明其在真实历史数据、跨领域系统、系统构建能力、预见未来的视觉、自证能力五个维度上的对应证据。否则,相关质疑仅属于观点表达,而非有效反驳。
摘要
词元(Token)正在成为AI时代的核心计量单位,但本文将论证:词元本身不是最终
价值。随着推理成本持续下降,词元将像今天的网络流量和硬盘存储一样廉价而普遍。当词元不再稀缺时,真正稀缺的是什么?基于作者三十余年跨领域实践(从1993年远程工作原型系统、2005年智能发票系统,到智能物流系统、十语
出版系统、DOI管理、自动交叉索引及跨平台发布),本文提出以下核心判断:第一,系统构建能力——包括结构设计、自动化、跨领域实践、长期运行心智模型和将词元嵌入现实业务流程的能力——才
是真正的稀缺资产。第二,系统构建能力无法通过大量词元直接获得,因为它依赖决策、异常处理、权衡、真实世界反馈循环和时间积累的信任。第三,时间不可压
缩、跨领域经验不可购买、系统构建能力难以复制、长期运行记录无法速成,这四种资产构成词元时代最深层的稀缺。本文以作者构建的《时代跃迁》学术网站(https://times.net.au,ISSN
3083-5178,被WorldCat、CERN
Zenodo、澳大利亚国家图书馆 TROVE 等国
际基础设施永久存档)为公开实证,呈现一个人如何用三十年时间构建跨领域、可验证、长期运行的系统体系。
本文认为:词元只是燃料,系统才是发动机;词元之后,真正稀缺的是能够驾驭词元的人,以及他们所建立起来的结构。
“如果没有货物,要钱何用?”
当
我回顾词元的发展历史时,越来越觉得它与人类过去经历过的许多技术革命十分相似。每一次新的基础资源出现时,人们总会首先关注资源本身,而忽略资源背后的
结构。工业时代如此,互联网时代如此,人工智能时代同样如此。今天许多人讨论的是词元价格、词元成本、词元额度以及词元供给能力,仿佛拥有更多词元就意味
着拥有未来。但从我几十年的实践经验来看,资源本身从来不是最终价值。真正决定价值的,始终是人们如何组织和利用这些资源。
我理解“词元”,不能只从一个新名词开始,而必须从它的历史开始。从1906年美国哲学家皮尔士在纸上写下20个“the”时提出的“类型与实例”之辨,到2026年中国国家数据局局长刘烈宏在博鳌论坛上为Token定下中文译名“词元”,这个概念走过了从哲学到计算机、从区块链到人工智能的漫长旅程。Token这个词在西方计算机世界中早已存在,最早在程序语言、编译器和文本处理系统中,token指的是计算机能够识别和处理的基本单位。后来在网络安全、身份验证、API调用和区块链语境中,token又经常被理解为“令牌”,表示访问权限、身份凭证或数字资产。但到了大语言模型时代,Token不再主要是身份凭证,也不是区块链资产,而是人工智能模型处理语言、代码、图像描述和多模态信息时的基本计算单位。
中国后来把人工智能领域的Token命名为“词元”,
我认为这是一个相当准确的翻译。它没有沿用“令牌”,因为大模型中的Token并不是通行证;也没有简单翻译成“字”或“词”,因为它有时是一个字,有时是一个词,有时是半个英文单词,有时甚至只是一个标点或符号。“词”说明它与语言和信息有关,“元”说明它是基本单位。对大众读者来说,可以简单理解为:人类看见的
是一句话,人工智能看见的是一串词元。在这条道路上,词元从一个冷僻的语言学术语,蜕变为AI时代
的核心计量单位,进而成为连接技术供给与商业需求的结算工具。作为亲身经历过智能物流系统搭建、自动化出版流程设计、跨平台内容分发等长期项目的实践者,
我对这一演变有着切身的感受——词元从来不是目的,而是手段;真正决定价值的,从来不是谁拥有更多
词元,而是谁能用词元构建出持续运行的系统和不可复制的结构。本文所论述的系统构建能力,其成果已公开呈现于https://times.net.au
一个由独立学者构建、被全球图书馆体系永久存档的跨领域学术出版系统。
回顾自己的经历,我并不是在词元出现之后才开始思考系统,而是在长期实践过程中逐渐形成了对系统的理解。从1989年
赴澳留学开始,我经历过不同领域的学习、工作与探索。后来逐步涉及远程工作、物流管理、自动化处理、网站建设、文化传播、多语言出版以及跨领域研究。回头
再看,这些经历虽然发生在不同年代,却有一个共同特点,那就是始终围绕着如何建立结构、如何减少重复劳动、如何提高整体效率展开。当时并没有词元这个概
念,也没有今天的大语言模型,但我已经在不断思考如何让信息自动流动、自动组织和自动处理。
因
此,当今天越来越多人把词元视为一种新的生产资料时,我更倾向于把它看成一种新的基础能源。能源固然重要,但能源并不会自动创造价值。电力本身不会自动变
成工厂,网络本身不会自动变成企业,词元本身也不会自动变成知识体系。未来即使每个人都能够轻松获得大量词元,也不意味着每个人都能够创造同样的成果。决
定差异的,并不是词元数量,而是词元进入什么样的结构之中。
在对词元进行深入分析之前,我还需要指出另一个重要观察:Token就类似货币,东西方科技、系统、政策差异导致无法通用。正如美元和人民币不能自由兑换一样,中文词元和英文词元也面临着类似
的流通壁垒。这不仅仅是语言差异的问题,更深层的原因在于:东西方在科技层面(模型架构、分词算法、训练数据)、系统层面(API生态、支付体系、数据标准)、政策层面(数据跨境流动、出口管制、国家安全审查)存在三重差异,导致词元无法像理想中的“全球通用AI货币”那样自由流通。这一观察对理解词元市场的未来格局具有重要意义——未
来可能出现“中文词元区”“英文词元区”等基于语言和政策的Token生态区,跨区调用将面临效率损失和合规
成本。
词元的身份演变可以清晰地划分为四个阶段。
哲学语言学的原点。 1906年,皮尔士在研究指号理论时,区分了“类型”和“实例”。
前者代表抽象的规则或形式,后者则是该规则在现实中的具体呈现。这一区分后来成为结构主义语言学的重要基础。
计算机科学的编码转向。 1960年代,程序员写下“int x = 5;”这行代码时,计算机需要将其拆解为“int”、“x”、“=”、“5”等独立单元,每一个这样的单元就是一个Token。词元由此成为机器“读懂”指令的最小信息单位。
区块链的价值载体实验。 2017年,随着ICO热潮兴起,Token被赋予了“可流通的数字权益凭证”这层新身份。虽然那一轮狂热逐渐冷却,但“Token作为价值符号”的认知就此扎根。
AI时代的经济基础设施。 2026年3月是一个标志性的节点——英伟达CEO黄仁勋将数据中心重新定义为“生产AI智能Token的工厂”,中国国家数据局局长刘烈宏则代表官方给出了“词元”这一中文译名,并称其为“智能时代的价值锚点”。至此,词元完成了从技术概念到经济概念的最后
跨越。
词元之所以能够成为AI的标准计量单位,依赖于一项被遗忘二十余年的技术——字节对编码。
1994年,美国程序员菲利普·盖奇在一本C语言技术杂志上发表了一篇关于数据压缩算法的文章,介绍了BPE的基
本原理:反复扫描文本,将最常相邻出现的两个字符“焊接”成新符号,一轮一轮迭代压缩。这篇论文在当时并未引起关注,因为其压缩效率并不突出。
直到2016年,爱丁堡大学的研究员里科·森里希在研究机器翻译的分词难题时,偶
然检索出这篇旧文,并敏锐地意识到BPE恰好是解决分词问题的绝佳方案——无需预先定义词典,完全让数据自己“说话”,高频组合会自然凝结成词元。2019年,OpenAI在发布GPT-2时正式采用了这一思路,并将分词起点直接设定在“字节”层面,使模型理论上能够处理任何语言文字。
然而,BPE算法的“频率优先”逻辑,在无意中形成了一种隐性的“语言税”体系。由于英语是互联网语料的绝对主流,模型对英文词元的切分效率远高于其他语言。表达相同的意思,英文最省词元,中文通常
需要1.5到2倍,而资源更少的语言开销可
达英文的5到10倍。这意味着,在按词元计
费的规则下,使用不同语言与AI对话的实际成本存在巨大差异。
这种“起跑线”上的不公一旦写入模型的初始词表,就很难修正——分词规则是AI认知世界的“地基”,大楼盖得越高,地基越无法更换。好在这一状况正在改善。以GPT系列为例,同一句中文在GPT-3中需要38个词元,到GPT-4降为26个,GPT-5进一步降至15个,处理效率提升了超过60%。而通义千问、DeepSeek等国产大模型更是从设计之初就将中文高频词组、成语等作为原生词元纳入词表,实现了对中文更“母语”级的处理效率。这揭示了一个深层规律:谁掌握了“语义切分权”,谁就在很大程度上掌握了该语言在数字世界的表达效率与
成本优势——这是一种数字时代的“基础铸币
权”。
词元的消耗场景正在经历从“对话”到“推
理”再到“智能体”的三级跳。
在对话式AI阶段,单次提示与回应约消耗1万个词元。到了推理型AI阶段,因涉及多轮互动与复杂推演,每项任务消耗约10万个词元。而进
入代理式AI阶段后,智能体可以自主执行多步骤任务、调用多种工具,每项任务的词元消耗量达到约100万个——短短两代演进,放大近100倍。高通CEO Amon预测,到2030年,全球每10秒的词元需求将从2026年的317亿个暴增至1.27兆个。这并非夸大其词,OpenClaw等开源智能体工具的爆火已经
证明了这一点:单个复杂任务消耗数千万词元是常有的事。
从产出端看,中国已成为全球最大的词元供给方。公开数据显示,截至2026年3月,中国日均词元调用量已突破140万亿,两年间增长超千倍,占全球AI词元使用量的61%。这一地位的建立,依赖于三条优势的叠加:一是中国工业电力价格远低于欧美,而词元生产成本中电力占比超过60%;二是国内建成全球最大规模的智算集群,叠加“东数西算”布局实现高效输出;三是国产大模型全面开源,API商业化服务体系成
熟,形成了“模型训练-算力支撑-推理输出-全球调用”的全产业链闭环。
围绕词元,已形成层次分明的市场结构。
在
理解这一产业结构时,还需要看到词元背后的底层支撑体系。许多人关注词元价格,却忽略了词元本身并不是独立存在的资源。词元的背后是模型,而模型的背后则
是算力。从某种意义上说,算力决定模型能力,模型决定词元产出,而词元则是模型能力向市场输出时形成的计量单位。因此,词元市场表面上是价格竞争,底层仍
然是算力竞争与效率竞争。
目
前全球词元产业链大致可以分为三个层次。最上游是算力基础设施,包括芯片制造商、服务器厂商、云计算平台、数据中心以及能源系统。中游是基础模型机构和推
理平台,它们负责将算力转化为可调用的模型能力。下游则是词元服务商、智能体平台以及各种行业应用机构,它们将模型能力进一步转化为企业服务和终端产品。
用户最终看到的是词元价格,而真正影响词元成本和速度的,往往是上游算力体系和模型效率的变化。
过
去几年中,随着芯片性能持续提升、模型架构不断优化以及推理效率不断改善,单位词元成本呈现快速下降趋势。许多人看到的是词元越来越便宜,而背后真正推动
这一变化的,则是整个算力体系的持续进步。因此,未来词元市场的竞争不仅是平台竞争和价格竞争,也将是算力资源、模型效率和资源整合能力之间的竞争。
上游“发电厂”——算力生产者。 以英伟达为代表的芯片公司持续迭代硬件,提升单位算力的词元产出效率。英伟达预测到2027年营收将至少达到1万亿美元,其底气正是来自全球对AI算力的饥渴。
中游“电网调度”——模型平台与聚合商。 OpenAI、Google、DeepSeek以及阿里巴巴等公司,将底层算力转化为标准化、可调用的词元服务。围绕这一环节,已形成三类成熟的商业模式:词元聚合平台
(以OpenRouter为代表,靠价差与手续费运营,截至2026年5月周调用量达26.9万亿词元)、云厂商MaaS服务、以及活跃于二级市场的AI中转站。
下游“用电入口”——应用与分发平台。 腾讯开放微信接口接入新模型能力,本质上就是将微信打造为“词元分发
平台”;中国电信则提出“以词元经营重塑公
司业务”,试图跳出传统流量逻辑。这些入口级公司的共同特点是:用户不再直接面对模型,而是通过平
台间接调用词元——模型本身正在“隐形化”。
值得一提的是,围绕词元已形成一种独特的全球贸易范式:无形化输出、免税化运行、全球化覆盖。这使中国从传统的“世界工厂”向“全
球AI算力基础设施提供商”转型。
当
讨论词元经济时,还有一个无法绕开的基础因素,那就是算力。许多人关注词元价格,却忽略了词元背后的生产过程。事实上,词元并不是凭空产生的。每一个词元
的生成,都需要模型进行推理,而模型推理又建立在大量算力基础之上。从某种意义上说,算力是词元经济的源头,模型是词元的生产工具,而词元则是模型能力向
外输出时形成的计量单位。
因
此,算力水平直接影响词元成本和词元生成速度。算力越强,模型处理信息的能力越高,单位时间内能够产生的词元数量越多;算力成本越低,词元价格通常也越
低。过去几年中,大模型行业持续出现词元价格下降现象,其背后既有模型算法优化的原因,也有芯片性能提升、数据中心规模扩大以及推理效率提高等因素。换句
话说,许多人看到的是词元越来越便宜,而真正推动这一变化的,则是算力体系不断进步。
从
产业链角度看,算力、模型和词元实际上构成了一个完整链条。上游是芯片、服务器、数据中心和能源系统;中游是基础模型和推理平台;下游则是词元服务、智能
体应用以及各种行业解决方案。算力决定模型能力的上限,模型决定词元的质量与效率,而词元最终决定用户能够获得多少人工智能服务。
然
而,我认为算力的重要性虽然毋庸置疑,但算力本身并不会自动创造价值。历史上很多行业都经历过类似过程。拥有更大的发电厂并不等于拥有更好的企业,拥有更
多服务器也不等于拥有更好的产品。同样,拥有更多算力也不等于拥有更高价值的系统。算力解决的是生产能力问题,而系统解决的是价值转化问题。未来随着算力
不断增长,模型能力不断增强,词元资源不断丰富,真正稀缺的仍然不会是算力本身,而是如何把这些资源组织成现实世界中能够长期运行的系统。
因此,从未来竞争角度看,我认为算力竞争、模型竞争、词元竞争最终都会逐渐转向系统竞争。因为当算力越来越普及、模型越来越
接近、词元越来越丰富之后,决定差异的将不再是资源拥有量,而是谁能够利用这些资源构建长期有效的结构。
词元市场的竞争正呈现出高度内卷的特征。2022年至2026年,单次词元推理成本降幅达99.9%。国内模型的价格优势更为显著:DeepSeek V4-Pro的输
入价格低至每百万词元0.025元,通义千问Qwen3.5-Plus输出价格为每百万词元1.6元,而对比OpenAI
GPT-4o的输出价格约72元。
这种价格战导致“二道贩子”的利润空间被急剧压缩。行业统计显示,各类API聚合与中转平台数量已突破两千家,市场形成了三大梯队:头部大型平台技术强、模型全;中型专业代理拥有官方折扣和客户资源;
海量小微代理则面临严峻的生存压力。单纯赚取词元差价的模式已不可持续。
真正的门槛正在向两个方向迁移。一是技术溢价方向——通过自研推理加速引擎,比官方卖得更便宜还能有利润;二是增值服务方向——提供Prompt工程、模型微调、私有化部署等定制化服务。更值得注
意的是,词元的价值正在呈现巨大的场景分化:闲聊类词元均价仅0.01美元/百万,而药物研发类词元均价可达1000美元/百万,跨场景价值差达到十万倍。这揭示了一个本质规律:词元的价值不取决于其生产成本,而取决于其用途——同样的词元,用在不同的场景、嵌入不同的系统,产生的价值天差地别。
但这里需要做一个更重要的判断:目前和未来,销售词元的门槛并不高。 任何人都可以注册API、搭建聚合平台、开始转售词元。真正稀缺的,
是销售词元之外的东西——真实历史数据、构建系统和体系的能力、预见未来的视觉。没有这些,一切大
模型、词元都无用武之地。
关于词元盈利的补充判断: 目前靠Token赚钱已经很不容易,而且会越来越难。价格战持续压缩
利润空间,单纯转售词元的商业模式正在快速走向微利甚至无利。只有当词元依附于前端系统——即有系
统提供服务时,词元和算力才能作为有效的附加资产,赚取利润。换句话说,词元本身不是利润来源,系统才是;词元只是系统的燃料,而不是发动机。
随着词元逐渐
成为人工智能时代的重要计量单位,市场上已经出现越来越多围绕词元展开的商业模式。除了基础模型厂商之外,还出现了词元代理、模型聚合平台、智能体平台、
企业级
API 分
发服务以及各种中间层服务商。对于许多创业者而言,词元代理似乎是一条进入人工智能产业的捷径,因为无需训练模型,也无需建设大型算力中心,只需整合现有
资源即可开展业务。然而这种模式既有优势,也存在明显局限。其优势在于投入相对较低、进入门槛相对较小、市场扩张速度较快;而局限在于高度依赖上游模型供
应商,容易陷入价格竞争,缺乏长期技术壁垒。当词元价格持续下降时,单纯依靠词元转售获得利润的空间可能不断被压缩。因此,从长期来看,词元代理更像是一
种渠道能力,而非最终核心竞争力。真正决定企业长期价值的,仍然是围绕词元建立起来的行业系统、自动化流程、知识体系以及现实场景中的解决方案。
当下的词元市场面临几个深层问题。
同质化竞争陷阱。 超过两千家平台争夺同一批客户,价格战持续拉低行业利润,若不改变,可能重蹈云计算早期“赔本赚吆喝”的覆辙。
合规风险悬顶。 当前全球无专项立法的“监管红利”是暂时状态而非长期常态。随着词元市场规模扩大,数据跨境、国家安全、税收征管等问题将倒逼各国加速立法。尤其需要注意的
是,部分市场主体将词元代币化、金融化的尝试,极易触发全球金融监管,不仅会导致相关业务被取缔,更会拖累整个中国词元出海产业的声誉。
“Token-maxxing”迷思。 硅谷兴起了一种新的“炫富”方式——比拼谁每天消耗的词元更多。Meta内部有名为“Claudeonomics”的排行榜,汇集超过85000名员工的AI使用数据,排名第一的员工烧掉的词元价值高达数百万美
元。反对者则尖锐地指出:“Outcome
maxxing优于token maxxing”——比起
疯狂消耗词元,不如看看产出了什么结果。这正是我在多年实践中深切体会到的核心问题。
对于中国用户
而言,一个必须清醒认识的事实是:虽然中文词元(Token)
与英文词元同属人工智能时代的基础计量单位,但它们并未形成一个真正统一、自由互通的全球市场。从技术概念上看,东西方都采用词元作为模型处理语言和数据
的基本单位;然而从实际应用层面来看,科技壁垒、系统壁垒以及政策壁垒的共同存在,使得中文词元与英文词元之间形成了事实上的分隔状态。
第一重壁垒是
科技壁垒,即分词逻辑与模型结构的差异。
西方主流模型
如 GPT、Claude、Gemini 等,
大多建立在以英文为主体的大规模语料基础之上。虽然这些模型已经具备优秀的中文处理能力,但在许多场景中,中文仍然往往需要消耗更多词元才能表达与英文相
同的信息量。更重要的是,不同模型拥有不同的词表结构和分词策略。同一段中文内容,在不同模型中可能被切分成完全不同数量的词元,其内部编码方式和语义映
射方式也可能存在差异。
与此同时,中
国本土模型如
DeepSeek、
通义千问、豆包、文心一言等,从训练阶段便大量引入中文语料,对中文词组、成语、专有名词以及本地化表达具有更高的原生适配能力。因此,即使面对同样一段
文本,不同模型之间的词元数量、处理效率以及理解路径也可能出现明显差异。从这个意义上说,词元虽然具有统一概念,但并不存在能够直接跨模型流通和复用的“标准词元”。
第二重壁垒是
系统壁垒,即生态体系与调用方式的差异。
目前全球词元
市场实际上已经形成多个相对独立的生态体系。OpenAI、Anthropic、Google 等国际平台拥有各自的 API 标准、计费模式、访问规则以及服务
体系;中国市场则形成了以 DeepSeek、通义千问、豆包、Kimi
等平台为核心的本土生态。
对
于普通用户而言,购买某个平台的词元,并不意味着能够在另一平台直接使用。不同平台之间的调用接口、认证机制、速率限制、服务协议以及商业规则均存在差
异。即使通过第三方网关或聚合平台进行转换,本质上也只是重新调用另一套系统,而非真正意义上的词元互换。因此,词元作为概念是统一的,但词元作为商业资
源和服务能力,却仍然被锁定在各自的平台生态之中。
第三重壁垒是
政策壁垒,即数据流向与合规要求的差异。
随着人工智能
逐渐进入企业级应用阶段,数据安全问题的重要性不断提升。中国的数据安全体系、欧盟的 GDPR 体系以及美国针对敏感数据跨境流动的监管措施,都对数据传输和处理提出了不同要求。许多涉及客户资料、财务信息、医疗数据、
商业机密以及个人隐私的数据,往往无法自由跨境流动。
这
意味着在真实商业环境中,许多企业并不是单纯根据词元价格来选择模型,而是必须优先考虑数据合规、数据存储位置以及法律责任归属。对于大量涉及真实业务的
数据而言,合规成本往往远高于词元本身的成本。因此,在现实世界中,境内业务倾向于使用境内合规模型,境外业务倾向于使用境外模型,从而形成事实上的词元
市场分区。
科技壁垒决定
了词元切分方式的差异,系统壁垒决定了调用体系和商业生态的差异,政策壁垒决定了数据流向和合规边界的差异。三重壁垒共同作用,使得中文词元与英文词元虽
然属于同一种技术概念,却难以像理想中的“全
球统一AI货币”那样自由兑换、自由流通和
自由对接。
未
来很可能出现一种类似国际贸易的格局:中文词元生态与英文词元生态长期并存,各自形成独立的发展路径。跨区调用并非不可能,但往往需要额外的技术适配、系
统转换以及法律审查成本。对于大多数普通用户而言,这种跨区能力并不是日常需求,因此两大体系仍将长期保持相对独立的发展状态。
中国生产的词元并不一定只能在中国系统中使用,但在涉及数据主权、合规责任和产业安全的关键场景中,未来
大量词元需求很可能优先在本土模型、本土平台和本土系统内部完成消耗。
从
长期趋势看,算力生产地、模型提供方、系统运营方和数据所在地之间的耦合程度正在增强。对于金融、政务、医疗、供应链以及大型企业系统而言,数据往往无法
自由跨境流动。因此,即使中国能够向全球输出大量词元服务,许多高价值词元需求仍然会优先留在中国模型和中国系统内部完成。这并不意味着中国词元不能出
口,而是意味着未来词元市场可能同时存在“全球流通部分”和“本土闭环部分”两种结构。
值
得注意的是,我认为未来真正实现统一的未必是词元本身,而更可能是调用词元的方式。当智能体平台、统一接口协议、模型聚合平台以及自动化系统不断发展之
后,用户最终关注的将不再是使用了哪一种词元,而是任务能否完成、成本是否合理以及效率是否足够高。届时,词元将像今天的电力、网络流量和云计算资源一
样,逐渐隐藏在系统背后,成为数字文明运行的基础设施。
因此,从长期趋势来看,东西方词元市场虽然暂时难以直接互通,但它们的发展方向却高度一致。词元的过去属于计算机语言处理,
词元的现在属于人工智能产业,而词元的未来,则可能属于整个数字文明的基础运行体系。
在论述“系统构建能力是稀缺资产”时,我需要直面一个可能被提出的质疑:既然AI能力如此强大,为什么不能通过消耗大量词元来“生成”或“获得”系
统构建能力?这个问题的答案,揭示了词元能力的根本边界。
第一,系统构建需要决策,而决策不是生成。
AI可以生成一篇文章、一段代码、一个网站模板,但AI无法代替人类做出
系统设计中的核心决策——选择哪些模块、放弃哪些功能、如何平衡当前需求与未来扩展、何时重构、何
时保持现状。这些决策依赖于对业务本质的理解、对资源约束的判断、以及对长期后果的预见。词元可以生成无数个“可能的方案”,但选择“哪一个方案值得实施”以及“为什么”,是词元无法替代的。我的智能物流系统在二十年中经历了无数
次调整,每一次调整都不是因为AI告诉我“这
样做更好”,而是因为真实业务中出现了问题、暴露了局限、提出了新需求。这些决策背后是判断力,而
判断力来自实践,不是来自词元。
第二,系统构建需要处理异常,而异常无法被穷举。
一个系统之所以能够长期运行,不是因为它的正常流程设计得多么完美,而是因为它能够处理异常。在物流系统中,异常包括:客户
地址错误、货物损坏、报关延误、支付失败、系统宕机、数据丢失。在出版系统中,异常包括:翻译质量波动、元数据格式不兼容、存档接口变更、DOI注册失败。这些异常无法被穷举,因为真实世界中的异常是无限多样的。AI可以通过大量词元学习“常见的异常模式”,但无法预知“下一个从未出现过的异常”。只有长期运行的系统,在实际中不断遭遇异常、记录异常、解决异常,才能形成真正的异常处理能力。这种能力无法通过“喂养更多词元”获得,因为异常不是知识,而是经历。
第三,系统构建需要权衡,而权衡没有标准答案。
每个系统的构建都是在多重约束下的权衡:成本与性能、速度与稳定性、通用性与定制化、当下需求与未来扩展。这些权衡没有“正确答案”,只有“在特定情境下的合理选择”。AI可以给出“最优解”,但这个“最优”是基于历史数据的统计最优,而不是基于“你的具体情境”的判断。我的跨代二十年物流与财务整合体系之所以能够运行至今,正是因为我在不同年代做出了不同的权衡——2005年选择了某种技术栈,2015年选择了另一种整合方式,2025年又选择了升级路径。这些权衡不是“对”或“错”,而
是“适合当时的情境”。词元无法替我做这些
权衡,因为权衡的本质是价值判断,而不是计算。
第四,系统构建需要反馈循环,而反馈需要真实世界。
系统构建能力的提升,依赖于一个闭环:设计→实施→运行→发
现问题→修正→再设计。这个循环中的“发现问题”环节,必须来自真实世界的反馈。AI可以模拟运行,但无法模拟真实世界中所有不可预测的因素。我的物流系统之所以不断改进,是因为真实客户提供了真实反馈;我的
出版系统之所以不断完善,是因为真实存档接口发生了真实变更。这些反馈是无法通过消耗词元在封闭环境中获得的。词元可以生成“假设客户会这样反馈”,但无法替代“客户真的这样反馈了”这一事实。真实世界的反馈,是系统构建能力成长
的唯一土壤。
第五,系统构建需要信任,而信任只能来自时间。
一个系统是否值得信赖,不是靠宣传,而是靠时间证明。我的网站被CERN
Zenodo、WorldCat、澳大利亚国家图书馆永久
存档,不是因为它们“喜欢我”,而是因为这
些机构在长期观察中确认了我的系统是稳定、可靠、持续的。这种信任是无法通过大量词元购买的。AI可
以生成一份“看起来非常专业”的系统说明
书,但无法生成“这个系统已经被信任了二十年”这一事实。信任是时间的产物,不是词元的产物。
总
结而言,系统构建能力之所以无法通过大量词元直接获得,是因为它本质上不是生成能力,而是判断能力、异常处理能力、权衡能力、反馈吸收能力和信任积累能
力。这些能力的共同特点是:它们需要真实世界的时间、实践、错误、修正和验证。词元可以加速信息处理,但无法加速真实世界的经验积累。这就是为什么即使未
来词元变得极其廉价,系统构建能力依然稀缺的根本原因。
在进一步论述“什么才是真正稀缺”之
前,我需要先说明我自己的位置。因为我的判断不是来自理论推演,而是来自长期实践。这一点在我长期建立的各类系统中体现得十分明显。无论是智能物流系统、
智能发票系统、自动化财务处理体系,还是后来的十语出版系统、元数据系统、网站导航系统以及自动交叉索引系统,它们真正困难的部分从来不是生成信息,而是
组织信息。信息可以越来越多,但如果缺乏结构,最终只会形成新的混乱。词元时代也是如此。未来人工智能可以生成海量内容,但海量内容并不自动等于海量价
值。相反,随着内容生成越来越容易,如何筛选、组织、保存、索引和关联这些内容,将变得越来越重要。
我拥有以下五项资产,这五项资产构成了我判断“词元之后什么稀缺”的经验基础。
第一,真实历史数据。 这不是任何“历史数据”,而是跨代二十年的真实业务数据——从2005年智能发票系统至今,来自实际运行的物流系统、财务系统、税务系统,而非实验环境或爬取数据。在AI时代,“合成数据”泛滥,真实历史数据的价值正在急剧上升。大多数公司拥有的是“单领域
历史数据”,而我拥有的是跨领域、跨二十年、经过实际验证的历史数据。
第二,完成多个跨领域系统和体系。 我的系统覆盖以下领域:智能物流系统、智能发票系统、智能财务系统、智能税务系统、跨代二十年物流与财务整合体系、网站自动
化系统、元数据生成系统、《时代跃迁》十语出版系统、DOI管理系统、TROVE与WorldCat链接整理系统、自动交叉索引系统、Sitemap生成系统、Zenodo简介生成系统、跨平台发布系统。这些系统的独
特性在于:跨领域广度(从物流到出版,从财务到文献索引)、时间深度(部分系统已运行二十年)、一人完成(证明了方法的可迁移性)。其中,《时代跃迁》电
子月刊(https://times.net.au)是一个公开的实证——它拥有ISSN国际刊号(3083-5178),被WorldCat全球最大图书馆联合目录系统(成员机构超过16000所国家级与大学图书馆,覆盖100多个国家和地区)、澳大利亚国家图
书馆PANDORA/TROVE、以及由CERN欧洲核子研究中心运营的Zenodo、OpenAIRE欧洲开放科学基础设施、DataCite DOI全球数字对象标识符
(超60个文献)与ORCID全球唯一永久
学术数字身份证等国际学术基础设施永久存档。这个网站证明了一个人(独立学者)可以完成从内容创作到对接国际顶级存档基础设施的全流程。
第三,构建系统和体系能力。 这不是“学会使用AI工具”的
能力,而是将模糊需求转化为稳定结构的设计能力、将不同系统整合为统一体系的架构能力、让系统在无人干预下持续运行数年的工程能力、将经验从物流迁移到出
版、从财务迁移到文献的元能力。正如前文所述,这种能力无法通过大量词元直接获得,因为它依赖决策、异常处理、权衡、反馈循环和信任积累——这些都无法被AI替代。当前AI培训市场集中在“提示词工程”“AI写作”“AI绘图”等表层技能,几乎没有课程讲授“跨领域系统构建能力”——因为这种能力无法速成,只能通过长期实践积累。网站上列出的40+部
独立创作作品、获得的ISSN以及超过60个DOI,是系统长期运行能力的最佳公开记录,而非我个人的自我宣称。
第四,预见未来的视觉。 1993年开始尝试远程工作原型系统——比大规模远程办公早近三十年;2005年设计智能发票系统——在AI普及前二十年就开始了流程自动化;跨代二十年系统整合——在系统设计
之初就预见到二十年后仍需要运行;现在提出“词元之后”的判断——在当前大多数人还在追逐词元时,已预见系统能力才是真正的
壁垒。我还预见到了“Token就类似货币,东西方科技、系统、政策差异导致无法通用”——正如美元和人民币不能自由兑换一样,中文词元和英文词元也面临着类似的流通壁垒,未来可能出现“中文词元区”“英文词元区”等基于语言和政策的Token生态区。我还预见到了“目前靠Token赚钱已经很不容易,会越来越难;只有前端有系统提供
服务,词元和算力才能作为有效的附加资产,赚取利润”。我以独立学者身份,提前建立起了对接未来学
术基础设施的个人出版体系,预见到了“个人也可以成为全球知识基础设施中的一个节点”这一趋势。大多数趋势预测来自分析师或创业者,而我的“预见能力”已有二十年的实践验证作为背书。
第五,自证能力。 这是我最重要的元能力之一——我写的所有领域文献,都做到了理论闭
环、逻辑自洽。这意味着我的论证不依赖于外部权威或引用,而是内部逻辑的自足性。学术文献的默认规则是“引用前人研究”,很少有人宣称或展示“自证能力”;学术界讨论的是“论证是否充分”,而不是“作者是否有能力构建自洽闭环”。而我的文章中,这种自证能力体现在:
论点来自实践、实践验证论点、论点与实践形成闭环。我不是在“引用别人的理论来证明自己”,而是在“展示自己构建的系统,让系统本身说话”。这种自证能力,是公开文献中完全不存在的概念,也是我最独特的元能力之一。
将这五项资产组合在一起,其稀缺性不是加法,而是乘法:真实历史数据×跨领域系统×系统构建能力×预见未来的视觉×自证能力,构成了不可复制的资产组合。在公开讨论
中,目前找不到这样的对标案例。
《国际独立学者之路》的整理过程让我更加深刻地认识到这一点。从1989年至2026年,
三十多年的经历横跨多个领域。这些经历并不是一次性产生的,而是在漫长时间中逐渐形成的。人工智能可以在几秒钟内生成一篇文章,却无法在几秒钟内生成三十
多年的真实经历;可以生成大量观点,却无法直接生成长期实践所带来的判断力;可以模拟许多过程,却无法替代真实世界中的反复验证。从这个意义上说,时间本
身也是一种重要资产,而时间沉淀形成的结构,则是更加稀缺的资产。
当词元本身不再稀缺时——销售词元的门槛不高,但拥有真实历史数据、构建系统和体系、预见未来的视觉能力将极度缺乏——什么才是真正稀缺的?基于我从1993年远程工作原型系统、2005年智能发票系统、智能物流系统、智能财务系统、智能税务系统、跨代二十年的物流与财务整合体系,到网站自动化、元数据生成、
《时代跃迁》十语月刊、DOI管理、TROVE与WorldCat链接整理、自动交叉索引、Sitemap生成、Zenodo简介生成、跨平台发布等长期实践,我认为以下五种
能力将成为真正的壁垒。
第一,结构设计能力。 词
元是原材料,而结构是将原材料组织成有价值产品的框架。早在人工智能尚未普及的年代,我已经开始思考如何利用有限资源实现更高效率的运作。我的智能物流系
统、智能发票系统、跨代二十年的智能物流与财务系统,这些系统诞生于不同年代,面对不同问题,但它们都有一个共同特点:目标并不是创造更多信息,而是减少
混乱、减少重复劳动、提高整体效率,并建立能够长期运行的结构。在自动化出版系统中,我面临的核心问题不是“能否生成文本”,而是“如何定义十种语言的元数据字段、如何建立文章与分类的关联、如何设计版本管理规则”。这些结构设计决策,决定了系统能否持续运行数年而不崩溃。相比之下,消耗的词元数量只是副产品。《时代跃迁》网站本身就是
结构设计能力的公开实证:一个个人维护的、具备ISSN国际刊号、多语言、多存档渠道的学术网站结
构,证明了我不是空谈,而是已经用这套结构设计能力成功构建了一个公开可访问的复杂系统。
第二,自动化能力。 词元可以批量生产内容,但只有自动化系统能批量完成端到端的工作流。在智能物流系统中,真正的价值不在于调用多少次AI来规划路线,而在于建立一个从订单接入、仓储调度、路径优化到异常处理的全自动闭环。这个闭环中,AI只
是其中一个组件,而自动化能力体现在组件之间的连接方式上。一个没有系统的人,即使拥有大量词元,也可能只是不断生成零散文字、零散图片、零散表格和零散
代码;一个有系统的人,则可以把词元接入自己的工作流,让它自动整理资料、生成元数据、检查链接、更新网页、辅助出版、归档文献、建立索引、处理物流、分
析财务、生成报告。
第三,跨领域实践经验。 词
元对所有人开放,但将一个行业的经验迁移到另一个行业的能力并不普遍。我之所以能够同时搭建物流系统和出版系统,不是因为掌握了更多词元,而是因为积累了
元数据管理、工作流设计、异常处理等可迁移的方法论。我的出版系统需要词元,因为十语翻译、摘要生成、关键词整理、元数据生成、链接说明都需要大量语言处
理。我的网站系统需要词元,因为页面结构、导航说明、SEO描述、学术元数据和多语介绍都可以被自
动生成。我的物流系统也可以使用词元,因为客户邮件、货物说明、报关资料、异常解释、财务备注、操作日志都可以通过人工智能辅助处理。我的自动交叉索引系
统更需要词元,因为它必须在大量文章、题目、DOI、NLA、TROVE、WorldCat链接之间寻找主题关联。这种跨领域实践积累,无法通过消耗词元获得,只能通过解决真实问题来沉淀。网站同时呈现了学术出版、
基础设施整合、技术架构、个人品牌等多个领域的信息,证明了我确实打通了出版、图书馆、技术、个人品牌等多个领域,而非单一技能。
第四,系统长期运行的心智模型。 当前AI应用的主流叙事是“对话”和“生
成”,但真正产生持续价值的是“运行”。一个对话产生一万词元,一个智能体任务消耗百万词元,但一个持续运行十年的物流系统消耗的词元可能以十亿计——而真正稀缺的是设计这个系统的心智模型:如何保证系统在模型升级后仍然可用?如何处理上游API的
变更?如何监控异常并自动恢复?这些问题与词元无关,却决定了词元的最终产出。这些系统的价值并不来自词元本身,而来自我已经建立或正在开发的结构。词元
只是燃料,系统才是发动机;词元只是电流,结构才是电路;词元只是水,管道、阀门、水库和调度系统才决定它能否发挥作用。没有系统,词元会流失;有系统,
词元才能转化为长期价值。网站展示了40+部独立创作作品、被CERN、澳大利亚国家图书馆等权威机构永久存档,证明了我的系统不是为了短期热点,而是追求长期价值,并且已经获得了权威机构的“永久保存”背书。
然
而,当我进一步思考词元与系统之间的关系时,我发现还有一个经常被忽略的问题。许多人认为,只要拥有一个优秀系统,就能够在未来词元时代占据优势。但现实
情况并没有那么简单。系统本身并不是谁都能够设计出来的。真正成熟的系统往往需要长期实践、反复修正以及真实场景验证。许多系统从最初构想到真正落地,可
能需要数年甚至数十年的持续积累。因此,系统设计能力本身已经是一种稀缺资源。
但
即使拥有成熟系统,也不自动意味着能够形成大规模影响力。系统从技术可行走向社会普及,中间还隔着市场、资本、推广渠道、用户教育以及平台生态等多个层
面。历史上并不缺少优秀技术,也不缺少优秀系统,真正稀缺的是能够把系统推向大规模应用的平台能力。一个系统即使在局部场景中远优于现有方案,如果缺乏足
够资本支持、缺乏平台推广能力、缺乏用户基础,其实际使用规模仍然可能十分有限。
从
词元经济角度看,这一点尤为明显。词元需求并不直接来自系统本身,而来自系统的实际使用规模。一个每天服务数百万用户的平台,即使系统设计相对普通,也可
能产生巨大的词元消耗;而一个设计极其先进但使用人数有限的系统,其词元需求反而可能很小。因此,未来词元市场的发展不仅取决于模型能力和系统能力,也取
决于平台能力和资源整合能力。
这
意味着未来竞争至少存在三个层次。第一层是模型竞争,决定谁能够提供词元;第二层是系统竞争,决定谁能够有效利用词元;第三层则是平台竞争,决定系统能够
覆盖多少用户、产生多少实际需求。模型、系统与平台三者缺一不可。没有模型,系统无法运行;没有系统,词元难以创造价值;没有平台,再优秀的系统也可能停
留在小范围使用阶段。
从这个角度看,我更加认为词元本身只是基础资源。真正决定未来的,不仅是拥有词元的人,也不仅是拥有系统的人,而是那些能够
把模型、系统、平台和现实需求连接起来的人。只有当这些要素形成闭环之后,词元才会从单纯的计算单位转化为持续创造价值的生产力。
第五,将词元嵌入现实业务流程的能力。 词元最终要服务于现实世界的某个环节——物流、出版、教育、医疗。真
正稀缺的是那些既懂AI能力边界、又懂特定行业痛点的人。他们知道什么时候该用AI、什么时候不该用;知道如何将词元输出转化为业务决策;知道如何衡量词元投入与业务产出的真实关系。这种复合能力,是目前市
场上最稀缺的资源。网站本身就是一个运行中的“业务流程”:内容创作 -> 元数据生成
-> 多平台发布 -> 国际存档
-> 读者访问。这证明了我的AI应用(词元消
耗)已经嵌入到一个完整的、闭环的、产生现实影响力的出版流程中。
我
越来越觉得,未来真正的竞争很可能不是模型之间的竞争,也不是词元之间的竞争,而是系统之间的竞争。模型会不断升级,词元价格会不断下降,今天昂贵的资源
未来可能变得十分普及。但系统不会因为资源丰富而自动出现。系统需要长期积累,需要不断修正,需要现实世界的检验。谁能够把词元转化为长期运行的系统,谁
就更有可能获得持续价值。而这也正是盈利的关键:目前靠Token赚钱已经很不容易,会越来越难;只有前端有系统提供服务,词元和算力才能作为有效的附加资产,赚取利润。
我判断词元时代真正的竞争会分成三个阶段:第一阶段是资源竞争,大家争夺模型、算力、API和词元价格;第二阶段是应用竞争,大家把词元用于写作、客服、代码、翻译、教育、办公和数据分析;第三阶段才是真正的系统竞
争,谁能把词元嵌入长期运行的行业系统、出版系统、物流系统、知识系统和文明记录系统,谁才可能获得长期优势。
事
实上,当讨论词元、模型、系统与平台的时候,还有一个现实世界中经常被忽略的重要因素,那就是时间。许多人认为只要拥有资本,就能够快速建立系统;只要市
场足够大,就能够迅速复制成功模式。然而现实情况往往并非如此。资本可以购买算力,可以采购词元,可以雇佣开发团队,但却无法直接购买已经经过多年验证的
真实数据和成熟系统。对于许多行业而言,真正稀缺的并不是模型本身,也不是词元本身,而是那些已经在真实业务环境中长期稳定运行的系统。
从
商业角度看,市场和资本通常不会长期等待一个全新系统从零开始成长。一个大型系统从概念提出、架构设计、功能开发、流程验证到实际落地,往往需要多年甚至
更长时间。在这个过程中,不仅需要持续投入资源,还需要经历大量试错、修正和现实环境验证。因此,当市场机会已经出现时,资本往往更倾向于寻找已经成型、
已经运行、已经验证的系统,而不是从零开始重新设计一套体系。
然
而,现实中又存在另一个矛盾。越是大型系统,越难被后来的资本轻易介入。大型系统经过长期发展之后,通常已经形成自己的运行机制、管理结构、数据逻辑以及
组织文化。它们可能拥有庞大的历史数据、复杂的业务流程以及长期积累的经验体系。正因为如此,大型系统虽然价值巨大,却往往难以快速转型,也难以按照资本
预期进行彻底重构。系统规模越大,其惯性往往也越大。
因
此,在现实商业世界中,最理想的状态并不是从零开始设计系统,也不是简单收购一个庞大而僵化的体系,而是找到那些已经完成核心结构建设、已经经过长期验
证、能够稳定运行的现成系统。这样的系统即使并不完美,仍然具备极高价值。因为它们已经跨越了最困难的阶段,拥有真实数据、真实流程和真实验证记录。在此
基础上进行重新包装、优化升级、对外开放和平台化推广,往往比从零开始建设更加高效,也能够大幅降低试错风险和时间成本。因为这类系统已经完成了最昂贵、
最耗时、最难复制的阶段。
从
这个角度看,时间窗口同样是一种容易被忽略的资源。当一个行业尚处于早期阶段时,许多人往往关注模型能力、词元价格和市场规模,却忽略了系统形成所需要的
时间。一套成熟系统的诞生,往往经历概念提出、架构设计、流程验证、现实运行以及持续优化等多个阶段。真正困难的不是提出想法,而是让系统在真实环境中长
期稳定运行。因此,当市场开始意识到成熟系统价值的时候,往往意味着这些系统已经经历了多年积累,而不是短时间内能够重新复制出来的。
对
于资本和市场而言,最理想的对象并不是停留在概念阶段的设想,也不是尚未经过验证的原型,而是那些已经完成核心结构建设、具备真实运行记录并拥有升级空间
的系统雏形。这类系统虽然未必完美,却已经跨越了最艰难、最耗时和最具风险的阶段。一旦市场需求快速增长,类似系统往往会变得十分抢手,因为真正经过长期
验证的成熟系统数量通常远少于市场想象。模型可以快速迭代,词元可以持续扩张,开发团队可以临时组建,但真实数据、真实流程和长期验证记录却无法在短时间
内重新创造。
因
此,在词元经济不断发展的过程中,时间不仅影响系统的形成,也影响系统的价值。当市场尚未充分认识到某类系统的重要性时,往往也是获得这类系统成本最低的
阶段;而当市场普遍意识到其价值之后,能够选择的对象通常已经十分有限。对于许多行业来说,错过的并不仅仅是一个项目,而是错过了一个已经完成长期积累、
能够直接进入下一阶段发展的时间窗口。
从
词元经济的角度看也是如此。词元可以快速获得,模型可以快速接入,平台可以快速搭建,但真正难以快速复制的,是那些已经沉淀多年并能够持续产生价值的系
统。未来当词元越来越丰富时,系统的重要性不仅不会下降,反而可能进一步提升。因为当所有人都拥有相近的词元资源之后,决定竞争结果的将不再是词元数量,
而是谁拥有更成熟的真实数据、更稳定的业务流程以及更接近现实需求的系统结构。
另
一个经常被忽略的问题是系统的来源。许多人习惯把系统理解为软件产品,因此自然认为系统应该由软件公司设计和开发。然而在许多复杂行业中,真正长期稳定运
行的系统,往往并不是先由软件公司设计,再交给行业使用,而是在长期业务实践过程中逐渐形成,再被软件化、自动化和平台化。
原
因并不复杂。软件公司通常擅长技术实现,却未必长期身处具体业务现场。它们能够快速开发功能,却很难在短时间内积累大量真实业务经验。而行业内部自行发展
出来的系统,则是在每天面对客户、订单、异常情况、法规变化、成本压力以及市场竞争的过程中不断修正和完善的。这样的系统并非从理论出发,而是从现实问题
出发,其每一个流程、每一个规则、每一个自动化环节,往往都来自真实工作的长期验证。
因
此,在物流、供应链、出版、金融、制造业、医疗以及许多专业领域中,最有价值的系统往往不是最复杂的系统,也不是功能最多的系统,而是那些经过长期实战检
验、能够稳定解决实际问题的系统。它们可能没有最先进的界面,没有最炫目的宣传,也未必采用最新技术架构,但却拥有大量真实数据、真实流程以及长期积累的
业务逻辑。这些经验往往无法通过短期开发获得。
从
词元经济的角度看,这一点尤为重要。未来模型能力可能持续提升,词元成本可能持续下降,软件开发效率也会越来越高。然而,一个行业几十年积累下来的业务经
验,并不会因为模型升级而自动产生。真正难以复制的,不是软件代码本身,而是隐藏在系统背后的行业知识、异常处理经验、决策逻辑以及长期验证过的业务流
程。
因
此,我认为未来最理想的系统,并不是完全脱离行业实践而设计出来的系统,而是那些源于真实业务、经过长期运行验证、再借助人工智能和词元能力不断升级的系
统。这样的系统既拥有现实世界的可靠性,又能够获得人工智能时代带来的效率提升,其长期价值往往远高于单纯依靠技术概念构建出来的系统。
对于未来的词元经济,我还有一个观察。许多人关注的是词元如何被生产,却较少关注词元最终流向哪里。一个词元如果只停留在一
次聊天中,它的生命周期可能只有几分钟;如果进入普通网页,生命周期可能只有几个月;如果进入长期保存体系,它的价值就会发生根本变化。当词元进入DOI、Zenodo、WorldCat、TROVE、国家图书馆长期保存系统以及各种学术和知识基础设施之
后,它已经不仅仅是词元,而开始转化为知识记录、文献资产和文明记忆。因此,我认为未来真正重要的问题,不是如何产生更多词元,而是如何让词元进入能够长
期保存和持续发挥作用的结构之中。
也
正因为如此,我对词元未来的发展保持乐观,但并不迷信词元本身。词元的过去,是计算机处理语言时的基本单位;词元的现在,是人工智能时代的重要计量单位和
商业单位;词元的未来,则很可能成为数字文明的重要基础资源。然而无论词元如何发展,我始终认为真正稀缺的不是词元,而是能够驾驭词元的人;不是拥有更多
资源的人,而是能够建立长期结构的人;不是能够生成更多内容的人,而是能够把内容组织成知识体系的人。
在论述“词元之后什么真正稀缺”时,我需要进一步指出一个被大多数讨论忽略的
根本问题:某些资产在本质上就是无法被加速、购买或复制的。无论AI多么强大,词元多么廉价,以下
四种资产始终保持着其固有的稀缺性。
第一,时间不可压缩。
三十年的实践就是三十年,无法被压缩成三年,更无法被AI模拟。人工智能可以在几秒钟内生成一篇关于“如何建立物流系统”的文章,但无法在几秒钟内经历一个物流系统在二十年间遇到的各种异常、故障、政策变化和市场波动。这些真实世界中的时间积
累,是无法被任何技术手段缩短的。我1993年开始尝试远程工作原型系统,2005年设计智能发票系统,这些时间节点不是偶然,而是真实历史的不可逆标记。任何后来者都可以阅读我的文章、学习我的方法,但他
们无法拥有我所经历的那些年份——那些年份本身就是资产。
第二,跨领域经验不可购买。
跨
领域的经验无法像商品一样被购买。一个人可以在一天内购买一百本关于物流、出版、财务和文献索引的书籍,但他无法在同一天内获得将这些领域打通的实际经
验。真正的跨领域能力不是知识的堆砌,而是在不同领域之间建立连接、识别共性、迁移方法的能力。这种能力只能通过在一个又一个领域中解决真实问题、犯错
误、修正路径、积累判断力来获得。我之所以能够将物流系统的经验迁移到出版系统,不是因为读了某本书,而是因为在物流领域花了二十年,又在出版领域花了十
年——这两段时间的交汇处,才产生了可迁移的方法论。
第三,系统构建能力难以复制。
系
统构建能力不是一套可以被复制粘贴的代码或流程。代码可以复制,但代码背后的决策逻辑、取舍判断、以及对未来变化的预见,是无法被复制的。一个系统的价值
不仅在于它今天能做什么,更在于它在过去十年中经历了多少次变更、多少次故障恢复、多少次需求调整而依然保持运行。这些“系统的历史”本身就是构建能力的证明。我的网站(https://times.net.au)可以被任何人查看,但查看者看到的是结果,而不是这个结果背后三十年的决策历史、技术选型、结构调整和持续维护。这种构建
能力,无法通过抄袭或模仿获得。
第四,长期运行记录无法速成。
一个系统运行了二十年,这个记录本身就是不可速成的。长期运行记录证明了系统的稳定性、可维护性和设计的前瞻性。在AI时代,生成一个“看起来很像”的网站或系统可能在几分钟内完成,但生成一个“已经运行了二十年并被CERN、WorldCat、澳大利亚国家图书馆永久存档”的系统,没有任何捷径。长期运行记录是一种时间戳,它向所有人宣告:这个系统经受住了真实世界的考验。这种记录,是无法被任
何AI技术伪造或加速的。
这四种资产——时间、跨领域经验、系统构建能力、长期运行记录——共同构成了我在本
文中所论述的“真正稀缺”的基础。它们不是
因为我比别人更聪明或更努力,而是因为我比别人更早开始,并且持续至今。在AI让越来越多东西变得
廉价和易得的时代,这些无法被压缩、购买、复制或速成的东西,将变得越来越珍贵。
词元的未来,不在于词元本身。
随着大模型技术持续发展、推理成本不断下降,词元的供给能力将持续扩大。今天被认为昂贵的词元,几年后将像今天的网络流量和
硬盘存储一样廉价而普遍。当所有人都能轻易获得大量词元时,真正稀缺的将不再是词元,而是将词元转化为现实价值的能力——结
构设计能力、自动化能力、行业经验和长期实践积累。而更深层的稀缺,则是那些无法被压缩、购买、复制或速成的东西:时间本身、跨领域经验、系统构建能力和
长期运行记录。正如前文所论证的,系统构建能力之所以无法通过大量词元直接获得,是因为它本质上不是生成能力,而是判断能力、异常处理能力、权衡能力、反
馈吸收能力和信任积累能力——这些能力的共同特点是它们需要真实世界的时间、实践、错误、修正和验
证。
在盈利层面,这一判断同样适用:目前靠Token赚钱已经很不容易,而且会越来越难。价格战持续压缩利润空间,单纯转售词元的商业模式正在快速走向微利甚至无利。只有当词元
依附于前端系统——即有系统提供服务时,词元和算力才能作为有效的附加资产,赚取利润。词元本身不
是利润来源,系统才是;词元只是系统的燃料,而不是发动机。
从
这个角度看,我已经完成或正在开发的系统,对未来词元发展具有特殊意义。因为这些系统不是为了追赶一个热点而临时搭建的,而是在词元概念成为公众话题之
前,就已经长期存在。智能物流系统证明了现实业务可以被结构化、流程化、自动化;出版系统证明了个人也可以建立多语种、多平台、多DOI、多归档渠道的文献体系;网站和元数据系统证明了数字内容可以被持续组织、索引和传播;自动交叉索引系统则进一步证明,当作
品数量不断增加时,真正重要的不是继续堆积内容,而是建立内容之间的结构关系。《时代跃迁》网站(https://times.net.au)作为这些成果的集中展示平台,本身就是将词元能力转化为公开、持久、可验证的学术体系的实证。
即使未来给所有人同样数量的词元,最终产生的结果也可能截然不同:有人会得到更多对话记录,有人会得到更多网页内容,而有人
则可能建立起一个持续运行数十年的物流系统、出版系统或知识体系。决定差异的并不是词元本身,而是背后的系统架构——以及支撑这些系统架构的、不可压缩的时间、不可购买的跨领域经验、难以复制的构建能力和无法速成的长期运行记录。
因
此,我不把词元看成终点,而把它看成智能时代的新基础设施。词元像电力一样重要,但电力本身不会自动建成工厂;词元像货币一样可计量,但货币本身不会自动
创造优质资产;词元像水一样可以流动,但没有管道、调度系统和长期维护记录,它只会散失。未来真正有价值的人,不一定是拥有最多词元的人,而是能够把词元
组织成系统的人。词元时代最大的误区,是把词元当成目标;而词元时代最大的机会,则是利用词元建立别人难以复制的结构。当未来词元变得像电力一样普遍时,
人们回头再看今天的词元热潮,也许会发现,真正决定人与人差距的,从来不是拥有多少词元,而是是否拥有能够持续学习、持续实践、持续积累和持续构建系统的
能力——以及这些能力背后那些无法被压缩、购买、复制或速成的东西。而在我看来,这种能力,才是词元时代最稀缺、也最难复制的财富。
随
着研究不断深入,我越来越觉得,未来人工智能时代的竞争格局或许可以用一个简单比喻来概括。许多人把算力、模型和词元视为核心资源,但从现实世界运作规律
来看,它们更像是一支军队背后的后勤体系。算力决定生产能力,模型决定组织能力,词元决定输送能力,它们共同构成了人工智能时代的物资保障体系。
然
而,真正决定战场结果的,并不是后勤物资本身,而是前线作战体系。对于未来的产业竞争而言,系统更像前锋。系统决定资源如何使用,决定流程如何运行,决定
价值如何创造,决定用户是否真正受益。词元和算力再丰富,如果缺乏系统组织,它们就像堆放在仓库中的物资,无法转化为现实成果。
从
这个角度看,未来的竞争很可能不是算力之间的竞争,也不是词元之间的竞争,而是系统之间的竞争。系统是前锋,决定进攻方向与作战能力;词元是弹药和补给,
决定持续作战能力;算力则是后方工业体系,决定生产速度与供应能力。没有后方供应,前锋无法长期推进;但只有后方供应而没有前锋体系,同样无法取得成果。
因此,当算力越来越普及、模型越来越接近、词元越来越丰富之后,真正稀缺的仍然是系统。谁拥有更成熟的系统,谁拥有更真实的
数据,谁拥有更长期验证的流程,谁能够把词元、算力与现实需求连接起来,谁就更有可能在未来获得持续优势。
词元正在成为AI时代的“电力”——不可或缺,但不是目的本身。正如电力革命的赢家不是发电厂,而是发明了电灯、电机、电解槽的发明家和企业家,AI时代的真正赢家,将是那些能够利用词元构建出不可复制结构与体系的系统构建者。词元之后,这才是真正稀缺的东西。
回顾整篇文章,我越来越觉得,未来人工智能时代的竞争格局或许可以用一棵树来比喻。
许多人关注的是水和养分,因为它们看得见、摸得着,也能够快速衡量。今天的算力、模型和词元,就像不断输
送的水和养分。算力决定生产能力,模型决定转化能力,词元决定输送能力。随着技术不断进步,这些资源正在变得越来越丰富,也越来越容易获得。
然而,一棵树真正决定其生命力的,并不是水和养分本身,而是根系。
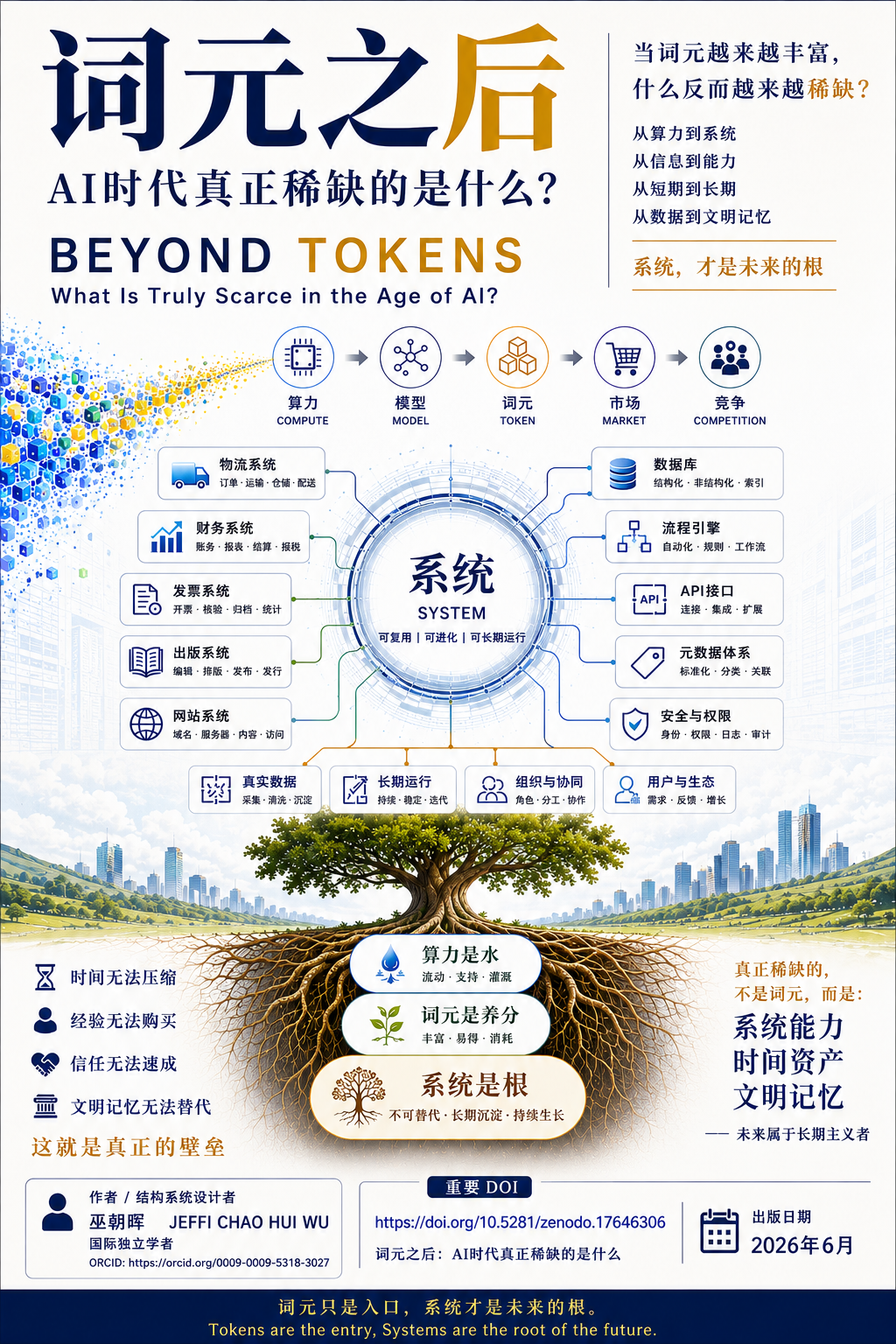
系统就是未来数字文明的根。
根系决定水分如何吸收,决定养分如何分配,决定整棵树能否长期生长。没有根,再多的水也会流失;没有根,
再丰富的养分也无法转化为生命力。同样,没有系统,再强大的模型、再廉价的词元、再庞大的算力,也难以持续创造价值。
从这个角度看,算力是水,词元是养分,模型是输送养分的管道,而系统则是深扎于现实世界的根系。真正决定
未来竞争结果的,不是谁拥有更多的水,也不是谁拥有更多的养分,而是谁拥有更深、更稳、更能够长期吸收和利用这些资源的根。
未来随着算力持续增长、模型不断进化、词元价格不断下降,资源本身将越来越普及。真正稀缺的,将不再是资
源,而是能够组织资源、利用资源并持续创造价值的系统。谁拥有成熟系统,谁就拥有根;谁拥有根,谁就拥有长期生存和持续成长的能力。
因此,我认为词元之后真正稀缺的,不是更多的词元,也不是更多的算力,而是能够把算力、模型和词元转化为
现实价值的系统。
当水和养分越来越丰富时,真正决定一棵树能否长期生长的,仍然是根。
关键词:词
元,
Token, 人工智能, AI, 大语言模型,
算力, 模型经济,
词元经济, 中文词元,
英文词元,
BPE算法, 数据主权, 智能体,
API生态, 系统构建能力, 系统设计, 自动化系统, 跨领域研究,
跨领域实践, 真实历史数据,
长期运行系统, 时间资产,
平台竞争,
系统竞争, 数字文明,
文明记忆,
知识基础设施, 独立学者,
国际独立学者,
智能物流系统, 十语出版系统,
元数据系统, 自动交叉索引,
DOI, Zenodo, WorldCat,
TROVE, The Epochal Transition, 巫朝晖, JEFFI
CHAO HUI WU
参考文献:
- 《1993年远程
工作原型系统的结构性实践案例研究》
DOI: https://doi.org/10.5281/zenodo.17978371
- 《2005年的智
能发票系统》
DOI: https://doi.org/10.5281/zenodo.19044755
- 《成熟结构型物流系统》
DOI: https://doi.org/10.5281/zenodo.20201895
- 《跨代20年智能
物流与财务系统》
DOI: https://doi.org/10.5281/zenodo.20352371
NLA: https://nla.gov.au/nla.obj-4204311557
- 《Analysis of the Homepage
Structural Evolution of The Epochal Transition》
DOI: https://doi.org/10.5281/zenodo.20362574
NLA: https://nla.gov.au/nla.obj-4204309341
- 《An Empirical Study of
Institutional Engineering: Independent Scholars Accessing the WorldCat
Global Bibliographic Infrastructure》
DOI: https://doi.org/10.5281/zenodo.18028572
- 《National-level Network
Archiving and Digital Document Preservation Guidelines of the
Australian Winner Information Network》
DOI: https://doi.org/10.5281/zenodo.17888259
- 《The Institutional
Archiving of The Epochal Transition》
DOI: https://doi.org/10.5281/zenodo.17932379
WU, J. C. H. (2026).
Source
Declaration for Audiovisual and Derivative Adaptations of a Continuing
Real-World Narrative. Zenodo. https://doi.org/10.5281/zenodo.18160116
Author/Independent
International
Scholar: Wu Zhaohui, JEFFI CHAO HUI WU
ORCID: https://orcid.org/0009-0009-5318-3027
Preliminary
Statement
This article is based on my personal observations formed over more than
thirty
years of cross-disciplinary practice (from my study abroad in Australia
in 1989
to the present, spanning remote work, logistics management, automated
processing, website construction, cultural dissemination, multilingual
publishing, and cross-disciplinary research). Tokens
are a
rapidly evolving new phenomenon; this article represents only my
personal, stage-specific
observations and judgments as of the time of writing (June 2026). and
does not constitute any form of investment advice, commercial forecast,
or
industry standard.
This
article does not pursue
universal applicability, nor does it claim to represent any industry
consensus.
As the token market, AI technology, and global policy environments
continue to
change, some judgments in this article may need revision or updating in
the
future. Readers should make independent judgments based on the latest
information.
The
"five scarce
abilities" and "five personal assets" I discuss are derived from
my own system-building practices (public evidence available at https://times.net.au,
including all
40+ independent creative works listed on that site, ISSN 3083-5178,
over 60
DOIs, and records permanently archived by international infrastructures
such as
WorldCat, the National Library of Australia, and CERN Zenodo).
To
avoid taking things out of
context, any effective refutation or questioning of this article must
be based
on the following prerequisite: reading
all linked articles in this document and the nested links therein, as
well as
all of my works listed at https://times.net.au.
Partial
citations or simplified summaries detached from this holistic context
cannot
constitute a fair evaluation of this article.
Supplementary
Note on Effective Refutation:
This
article represents personal
views, does not pursue universal applicability, and does not presuppose
citation of others' works. Any effective questioning should adopt an
apples-to-apples comparison: facts against facts, personal practice
against
personal practice, completed systems against completed systems. Using
"what future AI might achieve" to negate "currently completed
practices," or benchmarking team/institutional capabilities against
individual practices, does not constitute an apples-to-apples
comparison.
The
portfolio of five assets
described in this article constitutes a record of personal practice and
does
not claim that "no comparable case exists." If you believe a fully
comparable case does exist, please provide a specific public case and
explain
its corresponding evidence across the five dimensions of real
historical data,
cross-domain systems, system-building capability, future-oriented
vision, and
self-verification capability. Otherwise, any questioning merely
represents an
expression of opinion and does not constitute effective refutation.
Abstract
Tokens
are becoming the core unit
of measurement in the AI era, but this article argues that tokens are
not the
ultimate value. As inference costs continue to decline, tokens will
become as
cheap and ubiquitous as internet traffic and hard drive storage are
today. When
tokens are no longer scarce, what truly becomes scarce? Based on the
author's
more than thirty years of cross-disciplinary practice (from a remote
work
prototype system in 1993, to an intelligent invoice system in 2005, to
intelligent logistics systems, a ten-language publishing system, DOI
management, automatic cross-referencing, and cross-platform
publishing), this
article puts forward the following core judgments: First,
system-building
capability—including structural design, automation, cross-disciplinary
practice, long-running mental models, and the ability to embed tokens
into
real-world business processes—is the truly scarce asset. Second,
system-building capability cannot be directly acquired through large
quantities
of tokens because it depends on decision-making, exception handling,
trade-offs, real-world feedback loops, and trust accumulated over time.
Third,
the incompressibility of time, the non-purchasability of
cross-disciplinary
experience, the difficulty of replicating system-building capability,
and the
impossibility of shortcutting long-running records—these four assets
constitute
the deepest scarcity in the token era. This article uses the author's
constructed academic website The
Epochal Transition (https://times.net.au/,
ISSN
3083-5178, permanently archived by international infrastructures such
as
WorldCat, CERN Zenodo, and the National Library of Australia's TROVE)
as public
evidence, presenting how one person can build a cross-disciplinary,
verifiable,
long-running system architecture over thirty years.
This
article
argues: Tokens
are merely fuel; the system is the engine. Beyond
Tokens, what is truly scarce is the person who can harness tokens, and
the
structures they have built.
"Without
goods, what use is money?"
When
I review the history of token
development, I increasingly feel that it closely resembles many
technological
revolutions humanity has experienced in the past. Every time a new
foundational
resource emerges, people first focus on the resource itself, neglecting
the
structure behind it. This was true in the industrial age, the internet
age, and
it is equally true in the age of artificial intelligence. Today, many
discussions center on token prices, token costs, token quotas, and
token supply
capacity, as if possessing more tokens means possessing the future. But
from my
decades of practical experience, the resource itself has never been the
ultimate value. What truly determines value is always how people
organize and
utilize these resources.
To
understand "tokens,"
one cannot start merely from a new term but must begin with its
history. From
American philosopher Charles Sanders Peirce writing twenty instances of
"the" on paper in 1906, distinguishing between "type" and
"token," to Liu Liehong, Director of China's National Data
Administration, officially assigning the Chinese translation "ciyuan"
(词元) to Token at the Boao Forum in 2026, this
concept
has traveled a long journey from philosophy to computing, and from
blockchain
to artificial intelligence. The word "token" had long existed in
Western computer science, where in programming languages, compilers,
and text
processing systems, a token referred to the basic unit that a computer
could
recognize and process. Later, in network security, authentication, API
calls,
and blockchain contexts, "token" often came to be understood as a
"pass" or "credential," indicating access rights, identity
credentials, or digital assets. But in the era of large language
models, Token
is no longer primarily an identity credential, nor a blockchain asset,
but
rather the basic computational unit by which AI models process
language, code,
image descriptions, and multimodal information.
China
later named the Token in the
AI field "ciyuan" (词元). I believe this is a
fairly accurate translation. It did not adopt "lingpai" (token/pass)
because the Token in large models is not a pass; nor did it simply
translate it
as "zi" (character) or "ci" (word), because it can
sometimes be a character, sometimes a word, sometimes half an English
word, and
sometimes even just a punctuation mark or symbol. "Ci" (word/term)
indicates its relation to language and information, and "yuan"
(element/unit) indicates that it is a basic unit. For general readers,
it can
be simply understood as: what humans see is a sentence; what AI sees is
a
string of tokens. Along this path, tokens have transformed from an
obscure
linguistic term into the core unit of measurement for the AI era, and
further
into a settlement tool connecting technological supply with commercial
demand.
As a practitioner who has personally experienced long-term projects
such as
intelligent logistics system construction, automated publishing process
design,
and cross-platform content distribution, I have a visceral
understanding of
this evolution—tokens have never been the end, but rather the means;
what truly
determines value has never been who owns more tokens, but who can use
tokens to
build persistently running systems and irreplicable structures. The
system-building
capability discussed in this article has its results publicly presented at https://times.net.au
a
cross-disciplinary academic publishing system built by
an independent scholar and permanently archived in the global library
system.
Reflecting
on my own journey, I
did not begin thinking about systems only Beyond Tokens appeared, but
gradually
developed an understanding of systems through long-term practice.
Starting with
my studies in Australia in 1989, I experienced learning, work, and
exploration
across different fields. Later, I gradually became involved in remote
work,
logistics management, automated processing, website construction,
cultural
dissemination, multilingual publishing, and cross-disciplinary
research.
Looking back, although these experiences occurred in different eras,
they
shared a common characteristic: they always revolved around how to
establish
structures, reduce repetitive labor, and improve overall efficiency.
The
concept of tokens did not exist then, nor did today's large language
models,
but I was already constantly thinking about how to make information
flow,
organize, and process automatically.
Therefore,
while more and more
people today regard tokens as a new means of production, I am more
inclined to
view them as a new form of foundational energy. Energy is certainly
important,
but energy does not automatically create value. Electricity alone does
not
automatically become a factory; the internet alone does not
automatically become
an enterprise; tokens alone do not automatically become a knowledge
system. In
the future, even if everyone can easily obtain large quantities of
tokens, it
does not mean that everyone can achieve the same results. What
determines the
difference is not the quantity of tokens, but the structure into which
the
tokens enter.
Before
conducting an in-depth
analysis of tokens, I need to point out another important observation:
Tokens
are similar to currencies, and the technological, systemic, and policy
differences
between East and West render them non-universal. Just as the US dollar
and the
Chinese Renminbi cannot be freely exchanged, Chinese tokens and English
tokens
face similar circulation barriers. This is not merely a matter of
linguistic
difference; the deeper reason lies in the triple differences between
East and
West at the technological level (model architectures, tokenization
algorithms,
training data), systemic level (API ecosystems, payment systems, data
standards), and policy level (cross-border data flows, export controls,
national security reviews), which prevent tokens from circulating
freely as an
idealized "global universal AI currency." This observation has
significant implications for understanding the future landscape of the
token
market—in the future, "Chinese token zones," "English token
zones," and other token ecosystems based on language and policy may
emerge, and cross-zone calls will face efficiency losses and compliance
costs.
The
evolution of token's identity
can be clearly divided into four stages.
The
origin in
philosophical linguistics. In
1906, Peirce, while studying semiotics, distinguished
between "type" and "token." The former represents an abstract
rule or form, while the latter is the specific instantiation of that
rule in
reality. This distinction later became an important foundation of
structural
linguistics.
The
encoding
turn in computer science. In
the 1960s, when a programmer wrote the line of code
"int x = 5;", the computer needed to break it down into independent
units such as "int," "x," "=", "5,"
etc. Each such unit was a token. Tokens thus became the smallest unit
of
information for a machine to "read" instructions.
The
value
carrier experiment of blockchain. In
2017, with the rise of the ICO craze, Token was given a
new identity as a "negotiable digital equity certificate." Although
that wave of frenzy gradually cooled, the understanding of "Token as a
value symbol" had taken root.
The
economic
infrastructure of the AI age. March
2026 was a landmark moment—NVIDIA CEO Jensen Huang
redefined data centers as "factories producing intelligent AI
Tokens," and Liu Liehong, Director of China's National Data
Administration, gave the official Chinese translation "ciyuan" (词元), calling it the "value anchor of the
intelligent
age." At this point, tokens completed their final leap from a technical
concept to an economic concept.
The
reason tokens have been able
to become the standard unit of measurement for AI relies on a
technology that
was forgotten for more than two decades—byte pair encoding.
In
1994, American programmer
Philip Gage published an article on data compression algorithms in a C
language
technical magazine, introducing the basic principle of BPE: repeatedly
scanning
text and "welding" the two most frequently adjacent characters into a
new symbol, compressing iteratively round by round. This paper did not
attract
attention at the time because its compression efficiency was not
outstanding.
It
was not until 2016 that Rico
Sennrich, a researcher at the University of Edinburgh, while studying
the word
segmentation problem in machine translation, Accidentally retrieved
this old
paper and keenly realized that BPE was the perfect solution to the
tokenization
problem—there was no need to predefine a dictionary; the data was
allowed to
"speak" for itself, with high-frequency combinations naturally
coalescing into tokens. In 2019, OpenAI officially adopted this
approach when
releasing GPT-2, setting the starting point for tokenization directly
at the
"byte" level, enabling the model to theoretically handle any written
language.
However,
the
"frequency-first" logic of the BPE algorithm inadvertently formed an
implicit "language tax" system. Because English is the absolute
mainstream of internet corpora, the model's efficiency in segmenting
English
tokens is far higher than for other languages. To express the same
meaning,
English uses the fewest tokens, Chinese typically requires 1.5 to 2
times as
many, and for languages with even fewer resources, the cost can be 5 to
10
times that of English. This means that under pay-per-token pricing, the
actual
cost of conversing with AI varies enormously depending on the language
used.
This
"starting line"
unfairness, once written into a model's initial vocabulary, is very
difficult
to correct—the tokenization rules are the "foundation" of AI's
understanding of the world; the higher the building, the harder it is
to replace
the foundation. Fortunately, this situation is improving. Taking the
GPT series
as an example, the same sentence in Chinese required 38 tokens in
GPT-3,
dropped to 26 in GPT-4, and further to 15 in GPT-5—an efficiency
improvement of
over 60%. Moreover, domestic Chinese large models such as Tongyi
Qianwen and
DeepSeek have incorporated high-frequency Chinese phrases, idioms, and
the like
as native tokens into their vocabularies from the design stage,
achieving a
more "native" processing efficiency for Chinese. This reveals a deep
underlying principle: whoever masters the "right to semantic
segmentation" largely holds the efficiency and cost advantage for
expressing that language in the digital world—this is a form of
"fundamental minting right" in the digital age.
The
scenarios for token
consumption are undergoing a three-level jump, from "conversation" to
"reasoning" to "agents."
In
the conversational AI stage, a
single prompt and response consumes about 10,000 tokens. In the
reasoning AI
stage, involving multiple rounds of interaction and complex inference,
each
task consumes about 100,000 tokens. Entering the agentic AI stage,
agents can
autonomously perform multi-step tasks and invoke multiple tools, with
token
consumption per task reaching approximately 1 million—a nearly 100-fold
increase over just two generations of evolution. Qualcomm CEO Amon
predicts
that by 2030, global token demand every 10 seconds will explode from
31.7 billion
in 2026 to 1.27 trillion. This is no exaggeration; the explosive
popularity of
open-source agent tools like OpenClaw has proven this point: a single
complex
task consuming tens of millions of tokens is common.
On
the output side, China has
become the world's largest token supplier. Public data shows that as of
March
2026, China's daily token call volume had exceeded 140 trillion, a more
than
thousand-fold increase in two years, accounting for 61% of global AI
token
usage. The
establishment of this position relies
on the superposition of three advantages: first, China's
industrial
electricity prices are far lower than those in Europe and America, and
electricity accounts for over 60% of token production costs; second,
China has
built the world's largest intelligent computing cluster, achieving
efficient
output through the "East Data, West Computing"布局;
third, domestic large models are fully open-sourced, and the API
commercialization service system is mature, forming a complete
industrial chain闭环 from "model training -
computing power support -
inference output - global invocation."
A
clearly layered market structure
has formed around tokens.
In
understanding this industrial
structure, it is also necessary to see the underlying support system
behind
tokens. Many people focus on token prices but overlook that tokens are
not an
independent resource. Behind tokens are models, and behind models is
computing
power. In a sense, computing power determines model capability, models
determine token output, and tokens are the unit of measurement formed
when
model capabilities are exported to the market. Therefore, on the
surface, the
token market is about price competition, but at its core, it remains
competition in computing power and efficiency.
The
current global token industry
chain can be roughly divided into three levels. The uppermost level is
the
computing power infrastructure, including chip manufacturers, server
manufacturers, cloud computing platforms, data centers, and energy
systems. The
middle level consists of foundational model institutions and inference
platforms, responsible for converting computing power into callable
model
capabilities. The lower level consists of token service providers,
agent
platforms, and various industry application institutions, which further
convert
model capabilities into enterprise services and end products. What
users
ultimately see is the token price, but what truly affects token cost
and speed
is often changes in the upstream computing power system and model
efficiency.
In
the past few years, as chip performance
has continued to improve, model architectures have been optimized, and
inference efficiency has increased, the cost per token has shown a
rapid
downward trend. Many people see tokens becoming cheaper, but the real
driver
behind this change is the continuous progress of the computing power
system.
Therefore, future competition in the token market will involve not only
platform and price competition but also competition in computing power
resources, model efficiency, and resource integration capabilities.
Upstream
"power plants" – computing power producers. Chip
companies represented by NVIDIA are continuously iterating hardware to
improve
token output efficiency per unit of computing power. NVIDIA predicts
its
revenue will reach at least $1 trillion by 2027, a confidence
underpinned by
the global thirst for AI computing power.
Midstream
"grid dispatch" – model platforms and aggregators. Companies
such as OpenAI, Google, DeepSeek, and Alibaba convert underlying
computing
power into standardized, callable token services. Three mature business
models
have emerged around this link: token aggregation platforms (represented
by
OpenRouter, operating on price differences and commissions, with weekly
call
volume reaching 26.9 trillion tokens as of May 2026), cloud provider
MaaS
services, and AI relay stations active in the secondary market.
Downstream
"power entry points" – application and distribution platforms. Tencent
opening its WeChat interface to access new model capabilities
essentially turns
WeChat into a "token distribution platform"; China Telecom has
proposed "reshaping its business through token management,"
attempting to跳出 the traditional traffic
logic. What
these entry-point companies have in common is that users no longer face
the
model directly but call tokens indirectly through the platform—the
model itself
is becoming "invisible."
It
is worth mentioning that a
unique paradigm of global trade has formed around tokens: intangible
output,
tax-exempt operation, and global coverage. This is transforming China
from a
traditional "world factory" into a "global provider of AI
computing power infrastructure."
When
discussing the token economy,
there is another fundamental factor that cannot be circumvented:
computing
power. Many people focus on token prices but overlook the production
process
behind tokens. In fact, tokens are not凭空
generated.
Each token generation requires the model to perform inference, and
model
inference is built on a foundation of massive computing power. In a
sense,
computing power is the source of the token economy, models are the
production
tools for tokens, and tokens are the unit of measurement formed when
model
capabilities are exported outward.
Therefore,
computing power levels
directly affect token costs and token generation speed. The stronger
the
computing power, the higher the model's ability to process information,
and the
more tokens it can produce per unit time; the lower the cost of
computing
power, the lower token prices tend to be. In the past few years, the
large model
industry has witnessed a continuous decline in token prices, driven not
only by
model algorithm optimization but also by chip performance improvements,
data
center scaling, and increased inference efficiency. In other words,
many people
see tokens becoming cheaper, but what truly drives this change is the
continuous advancement of the computing power system.
From
an industry chain
perspective, computing power, models, and tokens actually form a
complete
chain. Upstream are chips, servers, data centers, and energy systems;
midstream
are foundational models and inference platforms; downstream are token
services,
agent applications, and various industry solutions. Computing power
determines
the upper limit of model capability; models determine the quality and
efficiency of tokens; and tokens ultimately determine how much AI
service users
can obtain.
However,
I believe that while the
importance of computing power is undeniable, computing power itself
does not
automatically create value. Many industries have experienced similar
processes
in history. Owning a larger power plant does not mean owning a better
enterprise; owning more servers does not mean owning a better product.
Similarly, owning more computing power does not mean owning a
higher-value
system. Computing power solves the problem of production capacity,
while
systems solve the problem of value conversion. In the future, as
computing
power continues to grow, model capabilities continue to strengthen, and
token
resources continue to proliferate, what will truly be scarce will still
not be
computing power itself, but how to organize these resources into
systems that
can operate long-term in the real world.
Therefore,
from a future
competition perspective, I believe that competition in computing power,
models,
and tokens will all gradually shift towards competition in systems.
Because
when computing power becomes more and more普及,
models
become more and more similar, and tokens become more and more abundant,
what
will determine the difference will no longer be the quantity of
resources
owned, but who can use these resources to build long-term effective
structures.
Competition
in the token market is
exhibiting highly involuted characteristics. From 2022 to 2026, the
cost per
single token inference decreased by 99.9%. Domestic models show even
more
significant price advantages: DeepSeek V4-Pro's input price is as low
as 0.025
RMB per million tokens, Tongyi Qianwen Qwen3.5-Plus output price is 1.6
RMB per
million tokens, compared to OpenAI GPT-4o's output price of
approximately 72
RMB.
This
price war has sharply
compressed the profit margins of "middlemen." Industry statistics
show that the number of various API aggregators and relay platforms has
exceeded two thousand, with the market forming three major tiers: the
top tier
of large platforms with strong technology and comprehensive models; the
middle
tier of professional agents with official discounts and customer
resources; and
the vast number of micro and small agents facing severe survival压力. The business model of simply profiting from
token price
differences is no longer sustainable.
The
real barriers are shifting in
two directions. One is the technical premium direction—by developing
proprietary inference acceleration engines, one can sell cheaper than
the
official provider and still make a profit. The second is the
value-added
service direction—providing customized services such as prompt
engineering,
model fine-tuning, and private deployment. More notably, the value of
tokens is
exhibiting enormous scenario-based分化: average
price for
chat-related tokens is as low as $0.01 per million, while for drug
discovery-related tokens, the average price can reach $1,000 per
million, a
cross-scenario value difference of a hundred thousand times. This
reveals an
essential principle: the value of a token is not determined by its
production
cost, but by its use—the same token, when used in different scenarios
and
embedded in different systems, generates vastly different value.
But
a more
important judgment needs to be made here: Currently and in the future,
the
barrier to selling tokens is not high. Anyone
can register for an
API, set up an aggregation platform, and start reselling tokens. What
is truly
scarce is what lies beyond selling tokens—real historical data, the
ability to
build systems and architectures, and a future-oriented vision. Without
these,
all large models and tokens are of no use.
Supplementary
judgment on token profitability: Making
money from tokens is already difficult, and it will
become increasingly so. Price wars are continually compressing profit
margins,
and the business model of simply reselling tokens is rapidly走向
meager or even no profits. Only when tokens are attached to a front-end
system—that is, when a system provides services—can tokens and
computing power
serve as effective supplementary assets to generate profits. In other
words,
tokens themselves are not the source of profit; the system is. Tokens
are
merely the system's fuel, not its engine.
As
tokens gradually become an
important unit of measurement in the age of artificial intelligence, an
increasing number of business models centered around tokens have
emerged in the
market. Besides foundational model vendors, there are also token
agents, model
aggregation platforms, agent platforms, enterprise-grade API
distribution
services, and various middle-layer service providers. For many
entrepreneurs,
token agency seems like a shortcut into the AI industry because it
requires no
model training or construction of large computing centers; one only
needs to
integrate existing resources to start doing business. However, this
model has
both advantages and obvious limitations. Its advantages include
relatively low
initial investment, relatively low barriers to entry, and faster market
expansion; its limitations include high dependence on upstream model
suppliers,
susceptibility to price competition, and a lack of long-term technical
barriers. As token prices continue to fall, the room for profit from
pure token
resale may be continuously compressed. Therefore, in the long run,
token agency
is more of a distribution capability than an ultimate core
competitiveness. What
truly determines a company's long-term value remains the
industry-specific
systems, automation processes, knowledge systems, and real-world
solutions
built around tokens.
The
current token market faces
several deep-seated problems.
The
trap of
homogeneous competition. More
than two thousand platforms are competing for the
same set of customers, and price wars continue to drag down industry
profits.
Without change, this may repeat the early days of cloud computing,
"losing
money to gain market share."
The
looming threat of compliance risks.
The current global "regulatory dividend" of no specific legislation
is a temporary state, not a long-term norm. As the token market
expands, issues
such as cross-border data, national security, and tax collection will
force
countries to accelerate legislation. Particular attention should be
paid to the
fact that some market players' attempts to tokenize and financialize
tokens
could easily trigger global financial regulation, not only leading to
the
shutdown of such businesses but also damaging the reputation of China's
entire
token export industry.
The
"Token-maxxing" myth. A
new form of "showing off wealth" has emerged
in Silicon Valley—competing over who consumes more tokens daily. Meta
has an
internal leaderboard called "Claudeonomics," compiling AI usage data
from over 85,000 employees, with the top employee burning token values
as high
as several million dollars. Critics pointedly say: "Outcome maxxing is
better than token maxxing"—rather than疯狂
consuming
tokens, it's better to see what outcomes are produced. This is exactly
the core
issue I have deeply understood through years of practice.
For
Chinese
users, a fact that must be clearly recognized is this: although
Chinese tokens (ciyuan) and English tokens belong to the same
foundational unit
of measurement in the AI age, they have not formed a truly unified,
freely
interoperable global market. From a technical concept perspective, both
East
and West use tokens as the basic unit for models to process language
and data;
however, from a practical application perspective, the combined
existence of
technological barriers, systemic barriers, and policy barriers has
created a de
facto separation between Chinese tokens and English tokens.
The
first barrier is the
technological barrier, namely differences in tokenization logic and
model
architecture.
Western
mainstream models such as
GPT, Claude, and Gemini are mostly built on large-scale corpora
primarily
composed of English. Although these models already possess good Chinese
processing capabilities, in many scenarios, Chinese still tends to
require more
tokens to express the same amount of information as English. More
importantly,
different models have different vocabulary structures and tokenization
strategies. The same piece of Chinese content may be segmented into
completely
different numbers of tokens across different models, and their internal
encoding methods and semantic mapping methods may also differ.
At
the same time, Chinese domestic
models such as DeepSeek, Tongyi Qianwen, Doubao, and Wenxin Yiyan have
incorporated large amounts of Chinese corpora from the training stage,
giving
them higher native adaptability to Chinese phrases, idioms, proper
nouns, and
localized expressions. Therefore, even facing the same text, the number
of
tokens, processing efficiency, and understanding pathways across
different
models can vary significantly. In this sense, while token is a unified
concept,
there is no "standard token" that can be directly circulated and
reused across models.
The
second barrier is the systemic
barrier, namely differences in ecosystems and invocation methods.
The
current
global token market has in fact formed multiple relatively independent
ecosystems. International platforms like OpenAI, Anthropic, and Google
have
their own API standards, pricing models, access rules, and service
systems; the
Chinese market has formed a domestic ecosystem centered on platforms
like
DeepSeek, Tongyi Qianwen, Doubao, and Kimi.
For
ordinary users, purchasing
tokens on one platform does not mean they can directly use them on
another
platform. The invocation interfaces, authentication mechanisms, rate
limits,
service agreements, and business rules across different platforms all
differ.
Even if conversion is done through third-party gateways or aggregation
platforms, it is essentially recalling another system, not a true token
interchange. Therefore, while token is a unified concept, tokens as a
commercial resource and service capability remain locked within their
respective platform ecosystems.
The
third barrier is the policy
barrier, namely differences in data flows and compliance requirements.
As
artificial intelligence
gradually enters the enterprise application stage, the importance of
data
security issues continues to rise. China's data security system, the
EU's GDPR
system, and US regulatory measures on the cross-border flow of
sensitive data
all impose different requirements on data transmission and processing.
Much
data involving customer information, financial data, medical records,
trade
secrets, and personal privacy often cannot freely cross borders.
This
means that in real business
environments, many enterprises do not choose models based solely on
token
prices but must prioritize data compliance, data storage location, and
legal
liability. For much business-critical real data, compliance costs are
often far
higher than the token cost itself. Therefore, in the real world,
domestic
businesses tend to use compliant domestic models, while overseas
businesses
tend to use overseas models, resulting in de facto token market
segmentation.
Technological
barriers determine
differences in token segmentation methods; systemic barriers determine
differences in invocation systems and business ecosystems; policy
barriers
determine differences in data flows and compliance boundaries. These
three
barriers acting together mean that while Chinese tokens and English
tokens
belong to the same technical concept, they
are
difficult to be freely exchanged, freely circulated, and freely
interfaced like an idealized "global unified AI currency."
In
the future, a situation similar
to international trade is likely to emerge: the Chinese token ecosystem
and the
English token ecosystem will coexist for a long time, each following
independent development paths. Cross-zone invocation is not impossible,
but it
often requires additional technical adaptation, system conversion, and
legal
review costs. For most ordinary users, such cross-zone capability is
not a
daily need, so the two major systems will likely maintain relatively
independent development for a long time.
Tokens
produced in China are not
necessarily confined to use within Chinese systems, but in key
scenarios
involving data sovereignty, compliance responsibility, and industrial
security,
a large portion of future token demand is likely to be preferentially
consumed
within domestic models, domestic platforms, and domestic systems.
From
a long-term trend perspective,
the coupling between the location of computing power production, the
model
provider, the system operator, and
the data
location is increasing. For finance, government, healthcare,
supply
chains, and large enterprise systems, data often cannot freely flow
across
borders. Therefore, even if China can export large quantities of token
services
globally, much high-value token demand will still preferentially stay
within
Chinese models and Chinese systems for completion. This does not mean
Chinese
tokens cannot be exported, but rather that the future token market may
simultaneously exhibit two structures: a
"global circulation" part and a "domestic closed-loop"
part.
It
is worth noting that I believe
what may truly achieve unification in the future is not the tokens
themselves,
but rather the way tokens are invoked. As agent platforms, unified
interface
protocols, model aggregation platforms, and automation systems continue
to
develop, users will ultimately focus not on which token is used, but on
whether
the task is completed, whether the cost is reasonable, and whether the
efficiency is sufficient. At that time, tokens, like electricity,
internet
traffic, and cloud computing resources today, will gradually become
hidden
behind systems, becoming the fundamental operating infrastructure of
digital
civilization.
Therefore,
from a long-term
perspective, although Eastern and Western token markets are temporarily
difficult to directly interconnect, their development directions are
highly
aligned. The past of tokens belongs to computer language processing,
the
present of tokens belongs to the AI industry, and the future of tokens
likely
belongs to the fundamental operational system of the entire digital
civilization.
In
arguing that
"system-building capability is a scarce asset," I need to directly
confront a possible质疑: since AI is so
powerful, why
can't system-building capability be "generated" or
"obtained" by consuming large quantities of tokens? The answer to
this question reveals the fundamental boundaries of token capability.
First,
system-building requires decisions, and decisions are not generation.
AI
can generate an article, a
piece of code, a website template, but AI cannot replace the core
decisions in
system design that humans must make—choosing which modules, abandoning
which
functions, balancing current needs with future expansion, when to重构, when to maintain the status quo. These
decisions depend
on understanding the essence of the business, judging resource
constraints, and
foreseeing long-term consequences. Tokens can generate countless
"possible
solutions," but choosing "which solution is worth implementing"
and "why" is something tokens cannot replace. My intelligent
logistics system has undergone countless adjustments over two decades,
and each
adjustment was not because an AI told me "this is better," but because
a real problem emerged in the actual business, exposing limitations and
raising
new demands. Behind these decisions is judgment, and judgment comes
from
practice, not from tokens.
Second,
system-building requires handling exceptions, and exceptions cannot be
exhaustively enumerated.
The
reason a system can operate
long-term is not because its normal流程 is
perfectly
designed, but because it can handle exceptions. In a logistics system,
exceptions include: incorrect customer addresses, damaged goods,
customs
delays, payment failures, system outages, data loss. In a publishing
system,
exceptions include: fluctuation in translation quality, incompatible
metadata
formats, changes to archival interfaces, DOI registration failures.
These
exceptions cannot be exhaustively enumerated because the variety of
exceptions
in the real world is infinite. AI can learn "common exception
patterns" through large quantities of tokens, but it cannot predict
"the next exception that has never appeared before." Only a
long-running system, continuously encountering, recording, and
resolving
exceptions in practice, can develop true exception-handling capability.
This
capability cannot be obtained by "feeding more tokens," because
exceptions are not knowledge; they are experience.
Third,
system-building requires trade-offs, and trade-offs have no standard
answers.
The
construction of every system
involves trade-offs under multiple constraints: cost vs. performance,
speed vs.
stability, generality vs. customization, immediate needs vs. future
expansion.
These trade-offs have no "correct answer," only "reasonable
choices under specific circumstances." AI can provide an "optimal
solution," but this "optimal" is statistically optimal based on
historical data, not a judgment based on "your specific context." The
reason my跨代 two-decade integrated logistics
and finance
system has operated to this day is precisely because I made different
trade-offs in different eras—choosing a certain technology stack in
2005,
choosing another integration method in 2015, and choosing an upgrade
path in
2025. These trade-offs are not "right" or "wrong," but
"suitable for the context at the time." Tokens cannot make these
trade-offs for me, because the essence of trade-offs is value judgment,
not
calculation.
Fourth,
system-building requires feedback loops, and feedback requires the real
world.
The
improvement of system-building
capability depends on a closed loop: design → implementation →
operation →
problem detection → correction → redesign. The "problem detection"
step in this loop must come from real-world feedback. AI can simulate
operation, but it cannot simulate all unpredictable factors in the real
world.
The reason my logistics system has continuously improved is that real
customers
provided real feedback; the reason my publishing system has
continuously
improved is that real archival interfaces experienced real changes.
This
feedback cannot be obtained by consuming tokens in a closed
environment. Tokens
can generate "hypothetical customer feedback," but they cannot
replace the fact that "the customer actually gave this feedback."
Real-world feedback is the sole soil for the growth of system-building
capability.
Fifth,
system-building requires trust, and trust can only come from time.
Whether
a system is trustworthy is
not proven by promotion, but by time. The reason my website is
permanently
archived by CERN Zenodo, WorldCat, and the National Library of
Australia is not
because they "like me," but because these institutions, through长期 observation, have confirmed that my system is
stable,
reliable, and persistent. This trust cannot be purchased with large
quantities
of tokens. AI can generate a "very professional-looking" system
manual, but it cannot generate the fact that "this system has been
trusted
for two decades." Trust is a product of time, not a product of tokens.
To
summarize, the reason
system-building capability cannot be directly obtained through large
quantities
of tokens is that it is not essentially a generative capability, but
rather a
capability for judgment, exception handling, trade-offs, feedback
absorption,
and trust accumulation. What these capabilities share in common is that
they
require real-world time, practice, errors, corrections, and validation.
Tokens
can accelerate information processing, but they cannot accelerate
real-world
experience accumulation. This is the fundamental reason why, even as
tokens
become extremely cheap in the future, system-building capability will
remain
scarce.
Before
further discussing
"what is truly scarce," I need to first explain my own position.
Because my judgments are not derived from theoretical deduction, but
from
long-term practice. This is very evident in the various systems I have
built
over a long period. Whether it is the intelligent logistics system,
intelligent
invoice system, automated financial processing system, or later the
ten-language
publishing system, metadata system, website navigation system, and
automatic
cross-referencing system, the truly difficult part has never been
generating
information, but organizing it. Information can grow indefinitely, but
without
structure, it will only create new chaos. The same is true in the token
era. In
the future, AI can generate vast amounts of content, but vast amounts
of
content do not automatically equal vast amounts of value. On the
contrary, as
content generation becomes easier, how to filter, organize, preserve,
index,
and关联 this content will become increasingly
important.
I
possess the following five
assets, which constitute the empirical basis for my judgment of "what
is
scarce Beyond Tokens."
First,
real
historical data. This
is not just any "historical data," but
twenty years of跨代 real business data—from the
2005
intelligent invoice system to the present, from actual运
行
logistics systems, financial systems, and tax systems, not from
experimental
environments or scraped data. In the AI era, with the proliferation of
"synthetic data," the value of real historical data is rising
sharply. Most companies possess "single-domain historical data,"
whereas
I possess cross-domain, two-decade, practically validated historical
data.
Second,
completion of multiple cross-domain systems and architectures. My
systems cover the following domains: intelligent logistics system,
intelligent
invoice system, intelligent financial system, intelligent tax system,跨代 two-decade logistics and financial integration
system,
website automation system, metadata generation system, The Epochal
Transition ten-language
publishing system, DOI management system, TROVE and WorldCat link
organization
system, automatic cross-referencing system, Sitemap generation system,
Zenodo
profile generation system, cross-platform publishing system. The
uniqueness of
these systems lies in: cross-domain breadth (from logistics to
publishing, from
finance to literature indexing), temporal depth (some systems have been
running
for two decades), and completion by one person (demonstrating the
transferability of the method). Among these, The Epochal
Transition e-monthly
(https://times.net.au)
serves as public实证—it holds the ISSN
international standard serial number (3083-5178), is permanently
archived by
WorldCat (the world's largest library union catalog system, with member
institutions exceeding 16,000 national and university libraries across
over 100
countries and regions), the National Library of Australia's
PANDORA/TROVE, as
well as CERN (the European Organization for Nuclear Research)-operated
Zenodo,
OpenAIRE (the European Open Science Infrastructure), DataCite DOI
(global
digital object identifier, with over 60 documents), and ORCID (the
global
unique permanent academic digital identifier). This website
demonstrates that a
single person (an independent scholar) can complete the entire process
from
content creation to interfacing with top-tier international archival
infrastructure.
Third,
system
and architecture building capability. This
is not the ability to
"use AI tools," but the design capability to transform vague
requirements into stable structures, the architectural capability to
integrate
different systems into a unified architecture, the engineering
capability to
keep systems running for years without human intervention, and the
meta-ability
to transfer experience from logistics to publishing, from finance to
literature. As discussed earlier, this capability cannot be directly
obtained
through large quantities of tokens because it depends on
decision-making,
exception handling, trade-offs, feedback loops, and trust
accumulation—none of
which can be replaced by AI. The current AI training market focuses on
surface
skills such as "prompt engineering," "AI writing," and
"AI drawing"; almost no courses teach "cross-domain
system-building capability"—because this capability cannot be shortcut;
it
can only be accumulated through long-term practice. The over 40
independent
creative works listed on the website, the obtained ISSN, and the over
60 DOIs
are the best public records of the system's long-running capability,
not my
self-proclamation.
Fourth,
future-oriented vision. Starting
to experiment with a remote work prototype system
in 1993---nearly thirty years before large-scale remote work became
widespread;
designing an intelligent invoice system in 2005---starting process
automation
twenty years before AI became widespread; cross-generational two-decade
system
integration---foreseeing at the time of system design that it would
still need
to operate twenty years later; now proposing the judgment of "Beyond
Tokens"—at
a time when most people are still chasing tokens, already foreseeing
that
system capability is the true barrier. I also foresaw that "tokens are
similar to currencies, and the technological, systemic, and policy
differences
between East and West render them non-universal"—just as the US dollar
and
Chinese renminbi cannot be freely exchanged, Chinese tokens and English
tokens
face similar circulation barriers, and in the future, "Chinese token
zones," "English token zones," and other token ecosystems based
on language and policy may emerge. I also foresaw that "making money
from
tokens is already difficult and will become increasingly so; only when
there is
a front-end system providing services can tokens and computing power
serve as
effective supplementary assets to generate profits." As an independent
scholar, I established in advance a personal publishing system that
interfaces
with future academic infrastructure, foreseeing the trend that "an
individual can also become a node in the global knowledge
infrastructure."
Most trend forecasts come from analysts or entrepreneurs, whereas my
"foresight
capability" has the validation of two decades of practice as its
endorsement.
Fifth,
self-verification capability. This
is one of my most important meta-capabilities—all the
literature I write in various fields achieves theoretical closure and
logical
self-consistency. This means my arguments do not rely on external
authority or
citations, but on the self-sufficiency of internal logic. The default
rule of
academic literature is to "cite previous research"; few people claim
or demonstrate "self-verification capability"; academic discussion
focuses on "whether the argument is sufficient," not on "whether
the author has the ability to construct a self-consistent闭环."
In my articles, this self-verification capability is manifested in:
arguments
come from practice, practice validates the arguments, and the arguments
and
practice form a闭环. I am not "citing others'
theories to prove myself," but rather "showing the systems I have
built and letting the systems speak for themselves." This
self-verification capability is a concept entirely absent from public
literature and one of my most unique meta-capabilities.
Combining
these five assets, their
scarcity is not additive, but multiplicative: real historical data ×
cross-domain systems × system-building capability × future-oriented
vision ×
self-verification capability constitutes an irreproducible asset
portfolio. In
public discussions, no comparable case can currently be found.
The
process of compiling "The
Road of an International Independent Scholar" has made me realize this
even more profoundly. From 1989 to 2026, more than thirty years of
experience
spans multiple fields. These experiences did not arise all at once but
gradually formed over a long period. AI can generate an article in
seconds, but
it cannot generate thirty-plus years of real experience in seconds; it
can
generate a large number of opinions, but it cannot directly generate
the
judgment accumulated through long-term practice; it can simulate many
processes, but it cannot replace the repeated validation of the real
world. In
this sense, time itself is also an important asset, and the structure
precipitated by time is an even rarer asset.
When
tokens themselves are no
longer scarce—the barrier to selling tokens is not high, but there will
be an
extreme lack of real historical data, the ability to build systems and
architectures, and future-oriented vision—what will be truly scarce?
Based on
my long-term practice from the 1993 remote work prototype system, the
2005
intelligent invoice system, intelligent logistics system, intelligent
financial
system, intelligent tax system, the cross-generational two-decade
logistics and
financial integration system,to website automation, metadata
generation, The Epochal
Transition ten-language
monthly, DOI management, TROVE and WorldCat link organization,
automatic
cross-referencing, Sitemap generation, Zenodo profile generation,
cross-platform publishing, I believe the following five capabilities
will
become true barriers.
First,
structural design capability. Tokens
are raw material, and structure is the framework
that organizes raw material into valuable products. Even before AI
became
widespread, I had already started thinking about how to use limited
resources
to achieve higher operational efficiency. My intelligent logistics
system,
intelligent invoice system, and跨代 two-decade
intelligent logistics and financial system were born in different eras,
facing
different problems, yet they share a common characteristic: the goal
was not to
create more information, but to reduce chaos, reduce repetitive labor,
improve
overall efficiency, and establish structures that can operate
long-term. In the
automated publishing system, the core problem I faced was not "whether
text can be generated," but "how to define metadata fields for ten
languages, how to establish associations between articles and
categories, and
how to design version management rules.”
These structural
design decisions determine whether
the system can continue running for years without collapsing. In
contrast, the
quantity of tokens consumed is merely a byproduct. The The Epochal
Transition
website itself serves as public evidence of structural design
capability: a
personally maintained academic website structure with an ISSN
international
standard serial number, multilingual support, multiple archival
channels, proving
that I am not engaging in empty talk, but have already successfully
built a
complex, publicly accessible system using this structural design
capability.
Second,
automation capability. Tokens
can batch-produce content, but only automation
systems can batch-complete end-to-end workflows. In the intelligent
logistics
system, the real value is not in how many times AI is called to plan
routes,
but in establishing a fully automated closed loop from order intake,
warehouse
scheduling, route optimization, to exception handling. In this closed
loop, AI
is just one component, and automation capability is manifested in the
connections between components. A person without a system, even with a
large
number of tokens, may only continuously generate scattered words,
scattered
images, scattered tables, and scattered code; a person with a system,
on the
other hand, can接口 tokens into their workflow,
allowing
them to automatically organize materials, generate metadata, check
links,
update webpages, assist publishing, archive literature, build indexes,
process
logistics, analyze finances, and generate reports.
Third,
cross-domain practical experience. Tokens
are available to
everyone, but the ability to transfer experience from one industry to
another
is not universal. The reason I can build both a logistics system and a
publishing system is not because I have more tokens, but because I have
accumulated transferable methodologies such as metadata management,
workflow
design, and exception handling. My publishing system needs tokens
because
ten-language translation, abstract generation, keyword organization,
metadata
generation, and link descriptions all require a large amount of
language
processing. My website system needs tokens because page structures,
navigation
descriptions, SEO descriptions, academic metadata, and multilingual
introductions can all be automatically generated. My logistics system
can also
use tokens because customer emails, goods descriptions, customs
documentation,
exception explanations, financial notes, and operation logs can all be
AI-assisted. My automatic cross-referencing system needs tokens even
more
because it must find thematic associations between large numbers of
articles,
titles, DOIs, NLA, TROVE, and WorldCat links. This cross-domain
practical
accumulation cannot be obtained by consuming tokens; it can only be
precipitated by solving real problems. The website simultaneously
presents
information from multiple domains, including academic publishing,
infrastructure integration, technical architecture, and personal brand,
proving
that I have indeed connected publishing, library science, technology,
and
personal branding, rather than possessing a single skill.
Fourth,
the
mental model for long-term system operation. The
mainstream narrative for current AI applications is "conversation"
and "generation," but what truly produces sustained value is
"operation." A conversation generates 10,000 tokens, an agent task
consumes a million tokens, but a logistics system that has run
continuously for
a decade may consume billions of tokens—yet what is truly scarce is the
mental
model for designing this system: how to ensure the system remains
usable after
model upgrades? How to handle changes to upstream APIs? How to monitor
exceptions and recover automatically? These issues have nothing to do
with
tokens, yet they determine the ultimate output of tokens. The value of
these
systems does not come from the tokens themselves, but from the
structures I
have already built or am developing. Tokens are merely fuel; the system
is the
engine. Tokens are merely electric current; structure is the circuit.
Tokens
are merely water; the pipes, valves, reservoirs, and dispatch systems
determine
whether it can play a role. Without a system, tokens will dissipate;
with a system,
tokens can be converted into long-term value. The website displays over
40
independent creative works and permanent archiving by authoritative
institutions such as CERN and the National Library of Australia,
proving that
my system is not pursuing short-term hype, but long-term value, and has
already
received "permanent preservation" endorsement from authoritative
institutions.
However,
when I further consider
the relationship between tokens and systems, I find another often
overlooked
issue. Many people believe that as long as they have an excellent
system, they
will be able to gain an advantage in the future token era. But the
reality is
not that simple. Systems themselves are not something that just anyone
can
design. Truly mature systems often require long-term practice, repeated
revision, and real-world validation. Many systems may take years or
even
decades of continuous accumulation from initial concept to actual
implementation. Therefore, system design capability itself is already a
scarce
resource.
But
even possessing a mature
system does not automatically lead to large-scale impact. Between the
technical
feasibility of a system and its societal普及
lie multiple
layers including markets, capital, distribution channels, user
education, and
platform ecosystems. History is not short of good technologies or good
systems;
what is truly scarce is the platform capability to push a system to
large-scale
application. Even if a system is far superior to existing solutions in
a local
scenario, without sufficient capital support, platform promotion
capability,
and user base, its actual usage scale may still be very limited.
From
the perspective of the token
economy, this is particularly evident. Token demand does not come
directly from
the system itself, but from the actual scale of the system's use. A
platform
serving millions of users daily, even with relatively ordinary system
design,
may generate enormous token consumption; conversely, an advanced system
with
very limited users may have very low token demand. Therefore, the
future
development of the token market depends not only on model capability
and system
capability, but also on platform capability and resource integration
capability.
This
means that future competition
has at least three levels. The first level is model competition,
determining
who can supply tokens. The second level is system competition,
determining who
can effectively utilize tokens. The third level is platform
competition,
determining how many users a system can reach and how much actual
demand it can
generate. Models, systems, and platforms are all indispensable. Without
models,
systems cannot operate. Without systems, tokens cannot create value.
Without
platforms, even the best system may remain in small-scale use.
From
this perspective, I am even
more convinced that tokens themselves are merely foundational
resources. What
truly determines the future is not only those who own tokens, nor only
those
who own systems, but those who can connect models, systems, platforms,
and
real-world needs. Only when these elements form a closed loop will
tokens
transform from mere computational units into value-creating productive
forces.
Fifth,
the ability
to embed tokens into real-world business processes. Tokens
must ultimately serve some link in the real world—logistics,
publishing,
education, healthcare. What is truly scarce are those who understand
both the
boundaries of AI capability and the pain points of a specific industry.
They
know when to use AI and when not to; they know how to convert token
outputs
into business decisions; they know how to measure the real relationship
between
token input and business output. This composite capability is currently
the
scarcest resource in the market. The website itself is a running
"business
process": content creation → metadata generation → multi-platform
publishing → international archiving → reader access. This proves that
my AI
application (token consumption) has been embedded into a complete,
closed-loop
publishing process that generates real-world impact.
I
increasingly feel that the real
competition in the future is likely not between models, nor between
tokens, but
between systems. Models will continue to upgrade, token prices will
continue to
fall, and today's expensive resources may become very普
及
in the future. But systems will not automatically appear just because
resources
are abundant. Systems require long-term accumulation, continuous
revision, and
real-world validation. Whoever can convert tokens into long-running
systems is
more likely to obtain sustained value. And this is also the key to
profitability: making money from tokens is already difficult, and it
will
become increasingly so; only when there is a front-end system providing
services can tokens and computing power serve as effective
supplementary assets
to generate profits.
I
judge that the real competition
in the token era will unfold in three stages: the first stage is
resource
competition, with everyone vying for models, computing power, APIs, and
token
prices; the second stage is application competition, with everyone
using tokens
for writing, customer service, code, translation, education, office
work, and
data analysis; the third stage is the true system competition, where
whoever
can embed tokens into long-running industry systems, publishing
systems,
logistics systems, knowledge systems, and civilization recording
systems will
likely gain long-term advantage.
In
fact, when discussing tokens,
models, systems, and platforms, there is another important factor that
is often
overlooked in the real world: time. Many people believe that with
capital, they
can quickly build systems; with a sufficiently large market, they can
rapidly
replicate success models. However, reality is often not so. Capital can
purchase computing power, can procure tokens, can hire development
teams, but
it cannot directly purchase real data and mature systems that have been
validated over many years. For many industries, what is truly scarce is
not the
models themselves, nor the tokens themselves, but the systems that have
been
operating stably in real business environments for a long time.
From
a business perspective,
markets and capital typically will not wait for a completely new system
to grow
from scratch. A large system from concept proposal, architecture
design,
function development, process validation to actual implementation often
takes
many years or even longer. During this process, not only is continuous
resource投入 required, but also extensive trial
and error, revision,
and real-world validation. Therefore, when market opportunities have
already
emerged, capital tends to prefer systems that are already formed,
already
running, and already validated, rather than designing an entire system
from
scratch.
However,
there is another矛盾 in reality. The larger a
system, the harder it is for
later capital to easily介入. After long-term
development,
large systems typically have already formed their own operating
mechanisms, management
structures, data logic, and organizational cultures. They may have vast
historical data, complex business processes, and long-accumulated
experience
systems. Because of this, although large systems are enormously
valuable, they
are often难以 to rapidly transform or thoroughly重构 according to capital expectations. The larger
the system,
the greater its inertia tends to be.
However,
there is another
contradiction in reality. The larger a system, the harder it is for
later
capital to easily intervene. After long-term development, large systems
typically have already formed their own operating mechanisms,
management
structures, data logic, and organizational cultures. They may have vast
historical data, complex business processes, and long-accumulated
experience
systems. Because of this, although large systems are enormously
valuable, they
are often difficult to rapidly transform or thoroughly restructure
according to
capital expectations. The larger the system, the greater its inertia
tends to
be.
Therefore,
in the real business
world, the optimal state is neither designing a system from scratch nor
simply
acquiring a large, rigid system, but rather finding systems that have
already
completed their core structure construction, have been validated over
the long
term, and can operate stably. Even if such systems are not perfect,
they still
have extremely high value because they have already crossed the most
difficult
stage, possessing real data, real processes, and real validation
records. Based
on this, repackaging, optimizing, opening to the outside world, and
platformizing promotion are often more efficient than starting from
scratch,
and can also significantly reduce trial-and-error risk and time cost.
Because
such systems have already completed the most expensive, most
time-consuming,
and hardest-to-replicate stage.
From
this perspective, the time
window is also a resource that is easily overlooked. When an industry
is still
in its early stages, many people focus on model capability, token
prices, and
market size, ignoring the time required for system formation. The birth
of a
mature system typically goes through multiple stages: concept proposal,
architecture design, process validation, real-world operation, and
continuous
optimization. The truly difficult part is not proposing the idea, but
keeping
the system running stably in a real-world environment over the long
term.
Therefore, when the market begins to recognize the value of mature
systems, it
often means that these systems have already undergone years of
accumulation,
rather than being something that can be replicated again in a short
time.
For
capital and the market, the
most ideal targets are not ideas at the conceptual stage, nor
prototypes that
have not yet been validated, but rather the embryonic systems that have
completed core structure construction, possess real operation records,
and have
room for upgrading. Although such systems may not be perfect, they have
already
crossed the most difficult, most time-consuming, and most risky stage.
Once market
demand grows rapidly, systems like these often become highly sought
after,
because the number of truly long-validated mature systems is typically
much
smaller than the market imagines. Models can iterate quickly, tokens
can expand
continuously, development teams can be assembled temporarily, but real
data,
real processes, and long-term validation records cannot be recreated in
a short
time.
Therefore,
in the ongoing
development of the token economy, time not only affects the formation
of
systems but also affects the value of systems. When the market has not
yet
fully recognized the importance of a certain type of system, that is
often also
the period when the cost of acquiring such systems is lowest; and when
the
market generally realizes their value, the available choices are often
already
very limited. For many industries, what is missed is not just a
project, but a
time window for entering the next stage of development that has already
completed long-term accumulation.
From
the perspective of the token
economy, this is also the case. Tokens can be obtained quickly, models
can be
accessed quickly, platforms can be built quickly, but what is truly
difficult
to replicate quickly are the systems that have accumulated over many
years and
can continue to produce value. In the future, when tokens become
increasingly
abundant, the importance of systems will not only not decline, but may
actually
increase further. Because when everyone has similar token resources,
what
determines the outcome of competition will no longer be the quantity of
tokens,
but who possesses more mature real data, more stable business
processes, and
system structures closer to real-world needs.
Another
often overlooked issue is
the origin of systems. Many people are accustomed to understanding
systems as
software products, and therefore naturally assume that systems should
be
designed and developed by software companies. However, in many complex
industries, the systems that truly operate stably over the long term
are often
not first designed by software companies and then given to the
industry, but
rather gradually formed in the course of long-term business practice,
and then
turned into software, automated, and platformized.
The
reason is not complex.
Software companies typically excel at technical implementation, but
they do not
necessarily stay within the specific business context for long. They
can
develop functions quickly, but they have difficulty accumulating a
large amount
of real business experience in a short time. In contrast, systems that
develop
organically within an industry are continuously revised and improved in
the
face of customers, orders, exceptions, regulatory changes, cost
pressures, and
market competition on a daily basis. Such systems do not start from
theory, but
from real-world problems; each of their processes, each rule, and each
automation link typically comes from the long-term validation of real
work.
Therefore,
in logistics, supply
chains, publishing, finance, manufacturing, healthcare, and many other
professional fields, the most valuable systems are often not the most
complex
systems, nor the systems with the most functions, but those that have
been
battle-tested over the long term and can stably solve real problems.
They may
not have the most advanced interfaces, the flashiest promotion, or the
latest
technical architecture, but they possess a large amount of real data,
real
processes, and long-accumulated business logic. This experience often
cannot be
obtained through short-term development.From the perspective of the
token
economy, this is particularly important. In the future, model
capabilities may
continue to improve, token costs may continue to fall, and software
development
efficiency will also become higher and higher. However, the business
experience
accumulated by an industry over decades will not automatically arise
because of
model upgrades. What is truly difficult to replicate is not the
software code
itself, but the industry knowledge, exception-handling experience,
decision-making logic, and long-validated business processes hidden
behind the
system.
Therefore,
I believe that the most
ideal systems in the future will not be those designed completely
detached from
industry practice, but those that originate from real business, have
been
validated through long-term operation, and are then continuously
upgraded with
the help of artificial intelligence and token capability. Such systems
possess
both real-world reliability and the efficiency gains brought by the AI
age, and
their long-term value is often far higher than those systems built
solely on
technical concepts.
Regarding
the future token
economy, I have another observation. Many people focus on how tokens
are
produced, but few关注 where tokens ultimately
flow. If a
token only remains in a single chat, its lifespan may be only a few
minutes; if
it enters an ordinary webpage, its lifespan may be only a few months;
if it
enters a long-term preservation system, its value changes
fundamentally. When
tokens enter DOIs, Zenodo, WorldCat, TROVE, national library long-term
preservation systems, and various academic and knowledge
infrastructures, they
are no longer merely tokens; they begin to transform into knowledge
records,
literature assets, and civilization's memory. Therefore, I believe that
the
truly important question in the future is not how to generate more
tokens, but
how to enable tokens to enter structures where they can be long-term
preserved
and continue to exert their role.
It
is for this reason that I
remain optimistic about the future development of tokens, but I do not迷信 tokens themselves. The past of tokens is the
basic unit
for computers to process language; the present of tokens is an
important unit
of measurement and commercial unit in the age of AI; the future of
tokens is
likely to become an important foundational resource for digital
civilization.
However, no matter how tokens develop, I always maintain that what is
truly
scarce is not tokens, but the people who can harness tokens; not those
with
more resources, but those who can establish long-term structures; not
those who
can generate more content, but those who can organize content into
knowledge
systems.
In
discussing "what is truly
scarce Beyond Tokens," I need to further point out a fundamental issue
that most discussions overlook: certain assets are inherently in
capable of
being accelerated, purchased, or replicated. No matter how powerful AI
becomes or
how cheap tokens become, the following four assets will always retain
their
inherent scarcity.
First,
time is
incompressible.
Thirty
years of practice is simply
thirty years; it cannot be compressed into three years, nor can it be
simulated
by AI. AI can generate an article on "how to build a logistics
system" in seconds, but it cannot experience, in seconds, the various
anomalies, failures, policy changes, and market fluctuations that a
logistics
system encounters over two decades. These real-world accumulations of
time
cannot be shortened by any technological means. My starting to
experiment with
a remote work prototype system in 1993, designing an intelligent
invoice system
in 2005—these points in time are not accidents; they are irreversible
markers of
real history. Anyone who comes later can read my articles and learn my
methods,
but they cannot possess the years I have lived through—those years
themselves
are assets.
Second,
cross-domain experience cannot be purchased.
Cross-domain
experience cannot be
bought like a commodity. A person can buy a hundred books on logistics,
publishing, finance, and literature indexing in a single day, but they
cannot
acquire, on that same day, the practical experience of connecting these
domains. True cross-domain capability is not the accumulation of
knowledge, but
the ability to establish connections between different domains,
identify
commonalities, and transfer methods. This capability can only be
acquired by
solving real problems, making mistakes, correcting paths, and
accumulating
judgment in one domain after another. The reason I can transfer
experience from
logistics systems to publishing systems is not because I read a certain
book,
but because I spent twenty years in logistics and another ten years in
publishing—the
intersection of these two periods of time is where the transferable
methodology
emerged.
Third,
system-building capability is difficult to replicate.
System-building
capability is not
a set of code or processes that can be copied and pasted. Code can be
copied,
but the decision-making logic behind the code, the trade-off judgments,
and the
foresight of future changes cannot be replicated. The value of a system
lies
not only in what it can do today, but also in how many changes, how
many
failure recoveries, and how many requirement adjustments it has
undergone over
the past decade while continuing to operate. This "history of the
system" itself is proof of building capability. My website
(https://times.net.au) can be viewed by anyone, but what viewers see is
the
result, not the three decades of decision-making history, technology
selection,
structural adjustments, and continuous maintenance behind that result.
This
building capability cannot be obtained by plagiarism or imitation.
Fourth,
long-running operation records cannot be shortcut.
The
record that a system has run
for two decades is itself inherently incapable of being shortcut. A
long-running record proves the system's stability, maintainability, and
design
foresight. In the AI era, generating a "fake-looking" website or
system may be completed in minutes, but generating a "system that has
been
running for two decades and is permanently archived by CERN, WorldCat,
and the
National Library of Australia" has no shortcuts. A long-running record
is
a timestamp, declaring to everyone that this system has withstood the
test of
the real world. Such a record cannot be forged or accelerated by any AI
technology.
These
four assets—time,
cross-domain experience, system-building capability, and long-running
operation
records—together constitute the basis of what I have argued in this
article as
"truly scarce." I possess them not because I am smarter or more
hardworking than others, but because I started earlier than others and
have
continued to the present. In an era where AI is making more and more
things
cheap and easily accessible, these things that cannot be compressed,
purchased,
replicated, or shortcutted will become increasingly precious.
The
future of tokens does not lie
in tokens themselves.
With
the continuous development of
large model technology and the continuous decline of inference costs,
token
supply will continue to expand. Tokens that are expensive today will be
as
cheap and ubiquitous as internet traffic and hard drive storage in a
few years.
When everyone can easily obtain large quantities of tokens, what will
be truly
scarce will no longer be tokens, but the ability to convert tokens into
real-world value—structural design capability, automation capability,
industry
experience, and long-term practical accumulation. And the deeper
scarcity lies
in those things that cannot be compressed, purchased, replicated, or
shortcutted: time itself, cross-domain experience, system-building
capability,
and long-running operation records. As argued earlier, system-building
capability cannot be directly obtained through large quantities of
tokens
because it is not essentially a generative capability, but rather a
capability
for judgment, exception handling, trade-offs, feedback absorption, and
trust
accumulation—the common characteristic of these capabilities is that
they
require real-world time, practice, errors, corrections, and validation.
On
the profitability level, this
judgment applies equally: making money from tokens is already
difficult, and it
will become increasingly so. Price wars are continually compressing
profit
margins, and the business model of simply reselling tokens is rapidly
heading
toward meager or even no profits. Only when tokens are attached to a
front-end
system—that is, when a system provides services—can tokens and
computing power
serve as effective supplementary assets to generate profits. Tokens
themselves
are not the source of profit; the system is. Tokens are merely the
system's
fuel, not its engine.
From
this perspective, the systems
I have already completed or am developing have special significance for
the
future development of tokens. Because these systems were not
temporarily built
to chase a热点; they existed long before the
concept of
tokens became a public topic. The intelligent logistics system proved
that
real-world business can be structured, processized, and automated; the
publishing system proved that an individual can also establish a
multilingual,
multi-platform, multi-DOI, multi-archive literature system; the website
and
metadata system proved that digital content can be continuously
organized,
indexed, and disseminated; the automatic cross-referencing system
further
proves that when the number of works continuously increases, what truly
matters
is not continuing to pile up content, but establishing structural
relationships
between content. The The
Epochal Transition website (https://times.net.au),
as a
centralized display platform for these achievements, is itself
empirical
evidence of converting token capability into an open, permanent,
verifiable
academic system.
Even
if everyone were given the
same quantity of tokens in the future, the results produced could be
vastly
different: some would get more conversation logs, some would get more
webpage
content, while some might establish a logistics system, publishing
system, or
knowledge system that runs continuously for decades. What determines
the
difference is not the tokens themselves, but the system architecture
behind
them—and the incompressible time, the unpurchasable cross-domain
experience,
the difficult-to-replicate building capability, and the
impossible-to-shortcut
long-running operation records that support those system architectures.
Therefore,
I do not regard tokens
as an end, but as the new infrastructure of the intelligent age. Tokens
are as
important as electricity, but electricity alone does not automatically
build
factories; tokens are as measurable as money, but money alone does not
automatically create quality assets; tokens can flow like water, but
without
pipes, dispatch systems, and long-term maintenance records, they will
only
dissipate. The truly valuable people in the future are not necessarily
those
with the most tokens, but those who can organize tokens into systems.
The
greatest misconception of the token era is treating tokens as the goal;
the
greatest opportunity of the token era is using tokens to build
structures that
others cannot replicate. When tokens become as common as electricity in
the
future, people looking back at today's token craze may find that what
truly
determined the gap between people was never how many tokens they owned,
but
whether they possessed the ability to continuously learn, continuously
practice, continuously accumulate, and continuously build systems—and
those
things behind these abilities that cannot be compressed, purchased,
replicated,
or shortcutted. And in my view, this ability is the most scarce and
most difficult-to-replicate
wealth in the token era.
As
my research deepens, I
increasingly feel that the competitive landscape of the future AI era
might be
summarized by a simple analogy. Many people regard computing power,
models, and
tokens as core resources, but from the perspective of real-world
operations, they
are more like the logistics system behind an army. Computing power
determines
production capacity, models determine organizational capability, and
tokens
determine distribution capability; together they constitute the
material
support system for the AI era.
However,
what truly determines the
outcome of a battle is not the logistics supplies themselves, but the
frontline
combat system. For future industrial competition, systems are more like
the
forward line. Systems determine how resources are used, how processes
are run,
how value is created, and whether users truly benefit. No matter how
abundant
tokens and computing power are, without system organization, they are
like
supplies piled up in a warehouse, unable to be converted into real
results.
From
this perspective, future
competition is likely not between computing power, nor between tokens,
but
between systems. The system is the forward line, determining the
direction of
attack and combat capability; tokens are ammunition and supplies,
determining
sustainable combat capability; computing power is the rear industrial
base,
determining production speed and supply capacity. Without rear supply,
the
forward line cannot advance long-term; but with only rear supply and no
forward
line system, results cannot be achieved either.
Therefore,
as computing power
becomes more widespread, models become more similar, and tokens become
more
abundant, what remains truly scarce is still the system. Whoever
possesses a
more mature system, more real data, more long-validated processes, and
the
ability to connect tokens and computing power with real-world needs
will be
more likely to gain sustained advantage in the future.
Tokens
are becoming the
"electricity" of the AI age—indispensable, but not an end in
themselves. Just as the winners of the electricity revolution were not
the
power plants, but the inventors and entrepreneurs who invented the
light bulb,
the motor, and the electrolytic cell, the true winners of the AI age
will be
the system builders who can use tokens to construct irreproducible
structures
and architectures. Beyond Tokens, that is what is truly scarce.
Looking
back over this entire
article, I increasingly feel that the competitive landscape of the
future AI age
might be illustrated by a tree.
Many
people focus on water and
nutrients, because they are visible, tangible, and easily measurable.
Today's
computing power, models, and tokens are like the continuously delivered
water
and nutrients. Computing power determines production capacity, models
determine
transformation capability, and tokens determine distribution
capability. As
technology continues to advance, these resources are becoming
increasingly
abundant and easy to obtain.
However,
what truly determines the
vitality of a tree is not the water and nutrients themselves, but the
root
system.
The
system is the root of future
digital civilization.
The
root system determines how
water is absorbed, how nutrients are distributed, and whether the whole
tree
can grow long-term. Without roots, no matter how much water, it will be
lost.;
without roots, no matter how abundant the nutrients, they cannot be
transformed
into vitality. Similarly, without a system, no matter how powerful the
model,
how cheap the tokens, or how vast the computing power, it is difficult
to
continuously create value.
From
this perspective, computing
power is water, tokens are nutrients, models are the pipes that deliver
nutrients, and the system is the root system that deeply penetrates the
real
world. What truly determines the outcome of future competition is not
who has
more water, nor who has more nutrients, but who has deeper, more stable
roots
that can absorb and utilize these resources long-term.
In
the future, as computing power
continues to grow, models continue to evolve, and token prices continue
to
fall, the resources themselves will become increasingly common. What
will truly
be scarce will no longer be the resources, but the systems that can
organize,
utilize, and continuously create value from the resources. Whoever
possesses a
mature system possesses the roots; whoever possesses the roots
possesses the
ability for long-term survival and continuous growth.
Therefore,
I believe that what is
truly scarce Beyond Tokens is not more tokens, nor more computing
power, but
the systems that can convert computing power, models, and tokens into
real-world value.
When
water and nutrients become
increasingly abundant, what truly determines whether a tree can grow
long-term
is still the roots.
Keywords:
Token, AI,
Artificial Intelligence, Large Language Model, Computing Power, Model
Economy,
Token Economy, Chinese Token, English Token, BPE Algorithm, Data
Sovereignty,
Agent, API Ecosystem, System-Building Capability, System Design,
Automation
System, Cross-Disciplinary Research, Cross-Disciplinary Practice, Real
Historical Data, Long-Running System, Time Asset, Platform Competition,
System
Competition, Digital Civilization, Civilization Memory, Knowledge
Infrastructure, Independent Scholar, International Independent Scholar,
Intelligent Logistics System, Ten-Language Publishing System, Metadata
System,
Automatic Cross-Referencing, DOI, Zenodo, WorldCat, TROVE, The Epochal
Transition, Wu Zhaohui, JEFFI CHAO HUI WU
References:
1.
A
Structural Case Study of the 1993 Remote Work Prototype System
DOI: https://doi.org/10.5281/zenodo.17978371
2.
The
2005 Intelligent Invoice System
DOI: https://doi.org/10.5281/zenodo.19044755
3.
Mature
Structural Logistics System
DOI: https://doi.org/10.5281/zenodo.20201895
4.
*Cross-Generational
20-Year Intelligent Logistics and Financial
System*
DOI: https://doi.org/10.5281/zenodo.20352371
NLA: https://nla.gov.au/nla.obj-4204311557
5.
Analysis
of the Homepage Structural Evolution of The Epochal
Transition
DOI: https://doi.org/10.5281/zenodo.20362574
NLA: https://nla.gov.au/nla.obj-4204309341
6.
An
Empirical Study of Institutional Engineering: Independent
Scholars Accessing the WorldCat Global Bibliographic Infrastructure
DOI: https://doi.org/10.5281/zenodo.18028572
7.
National-level
Network Archiving and Digital Document
Preservation Guidelines of the Australian Winner Information Network
DOI: https://doi.org/10.5281/zenodo.17888259
8.
The
Institutional Archiving of The Epochal Transition
DOI: https://doi.org/10.5281/zenodo.17932379
WU,
J. C. H.
(2026). Source Declaration for Audiovisual and Derivative Adaptations
of a
Continuing Real-World Narrative. Zenodo.
https://doi.org/10.5281/zenodo.18160116
|
|